 新榜样老司机带你认识MySQL分布式存储
新榜样老司机带你认识MySQL分布式存储1、分布式应用的概念和优势
分布式数据库是指利用高速网络将物理上分散的多个数据存储单元连接起来组成一个逻辑上统一的数据库。分布式数据库的基本思想是将原来集中式数据库中的数据分散存储到多个通过网络连接的数据存储节点上,以获得更大的存储容量和更高的并发访问量。近年来,随着数据量的增长,分布式数据库技术也得到了快速的发展,传统的关系型数据库开始从集中式模型向分布式存储,从集中式计算走向分布式计算。
分布式数据库系统的主要目的是容灾、异地数据备份,并且通过就近访问原则,用户可以就近访问数据库节点,这样就实现了异地的负载均衡。同时,通过数据库之间的数据传输同步,可以分布式保持数据的一致性,这个过程完成了数据备份,异地存储数据在单点故障的时候不影响服务的访问,只需要将访问流量切换异地镜像就行。
分布式数据库应用的优势如下:
(1)适合分布式数据管理,能够有效提高系统性能。
(2)系统经济性和灵活性好。
(3)系统的可靠性和可用性强。
2、mysql分布式应用的主要技术
(1)mysql数据切割
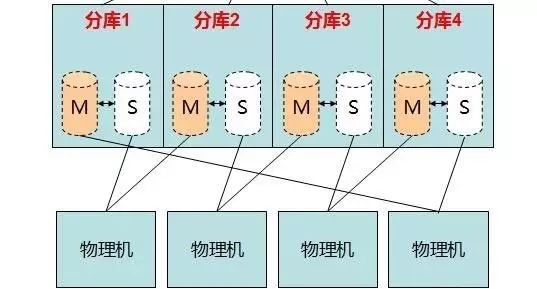
数据切割(sharding)是指通过某种特定的条件,将存放在同一数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。数据切分还可以提高系统的总体可用性,因为单台crash之后,只有总体数据的某部分不同,而不是所有数据。
根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表(或者schema)来切分到不同的数据库(主机)之上,这种切分成为数据的垂直(纵向切分);另一种则是根据表中数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称为数据的水平(横向)切分。垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各个业务之间耦合度低,相互影响小、业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表拆分到不同的数据库中。根据不同的表进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。水平切分比垂直切分更复杂一点。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身比较复杂,后期的数据维护也更加复杂一些。
(2)为什么要切分数据?
1)像Oracle这样成熟稳定的DB可以支撑海量数据的存储和查询,但是价格不是所有人都承受得起。
2)负载高点时,Master-Slaver模式中存在瓶颈。现有技术中,在负载高点时使用相关的Replication机制来实现相关的读写的吞吐性能。这种机制存在两个瓶颈:一是有效性依赖于读操作的比例,这里Master往往会成为瓶颈所在,写操作时需要一个顺序队列来执行,过载时Master会承受不住,Slaver的数据同步延迟也会很大,同时还会消耗CPU的计算能力,为write操作在Master上执行以后还是需要在每台slave机器上都跑一次。而Sharding可以轻松的将计算,存储,I/O并行分发到多台机器上,这样可以充分利用多台机器各种处理能力,同时可以避免单点失败,提供系统的可用性,进行很好的错误隔离。
3)用免费的MySQL和廉价的Server甚至是PC做集群,达到小型机+大型商业DB的效果,减少大量的资金投入,降低运营成本,何乐而不为呢?
Mysql5.1以上的版本都支持数据表分区功能。数据库中的数据在经过垂直或水平切分被存放在不同的数据库主机中之后,应用系统面临的最大问题就是如何让这些数据源得到较好的整合,有以下两种解决思路。
1)在每个应用程序模块中配置管理自己需要的一个(或者多个)数据源,直接访问各个数据库,在模块内完成数据的整合。
2)通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明。
第二种方案,虽然短期内需要付出的成本可能会大一些,但是对整个系统的扩展性来说,是非常有帮助的。针对第二种方案,可以思路如下:
1)利用mysql proxy实现数据切分及整合。
Mysql proxy是在客户端请求与mysql服务器之间建立一个连接池,所有客户端请求都发送到mysql proxy,由mysql proxy进行相应的分析,判断是读操作还是写操作,然后发送到相应的mysql服务器上。对于多节点slave集群,也可以做到负载均衡的效果。
2)利用amoeba实现数据切分及整合。
Amoeba是一个基于java开发的、专注于解决分布式数据库数据源整合proxy程序的开源框架,amoeba已经具有query路由,query过滤、读写分离、负载均衡以及HA机制等相关内容。Amoeba主要解决以下几个问题:
①数据切分后复杂数据源整合
②提供数据切分规则并降低数据切分规则给数据库带来的影响
③降低数据库与客户端的连接数
④读写分离路由
3)利用HiveDB实现数据切分及整合。
3、mysql读写分离
读写分离是利用数据库的复制技术,将读和写分布在不同的处理节点上,从而达到提高可用性和扩展性的目的。主数据库提供写操作,从数据库提供读操作,在很多系统中,更多地是读操作。当主数据库进行写操作时,数据要同步到从数据库,这样才能有效保证数据库完整性。Mysql也有自己的同步数据技术。Mysql通过二进制日志来复制数据,主数据库同步到从数据库后,从数据库一般由多台数据库组成,这样才能达到减轻压力的目的。读操作应根据服务器的压力分配到不同的服务器,而不是简单的随机分配。Mysql提供了mysql proxy实现读写分离操作。
目前较为常见的mysql读写分离分为以下两种。
①基于程序代码内部实现
在代码中根据select、insert进行路由分类,这类方法也是目前生产环境中应用最广泛的。
②基于中间代理层实现
代理位于客户端和服务器之间,代理服务器收到客户端请求后通过判断转发到后端数据库。下图是ebay读写分离的结构图,通过share plex近乎实时的复制数据到其他数据节点,再通过特定的模块检查数据库状态,并进行负载均衡、读写分离,极大地提高了系统可用性。
4、mysql集群
Mysql cluster技术在分布式系统中为mysql数据提供了冗余特性,增强了安全性,使得单个mysql服务器故障不会对系统产生巨大的负面效应,系统的稳定性得到保障。
Mysql cluster采用shared-nothing(无共享)架构。Mysql custer主要利用了NDB存储引擎来实现,NDB存储引擎是一个内存式存储引擎,要求数据必须全部加载到内存之中。数据被自动分布在集群中的不同存储节点上,每个存储节点只保存完整数据的一个分片(fragment)。同时,用户可以设置同一份数据保存在多个不同的存储节点上,以保证单点故障不会造成数据丢失。
Mysql cluster需要一组计算机,每台计算机的角色可能是不一样的。Mysql cluster按照节点类型可以分为3类:管理节点(对其他节点进行管理)、数据节点(存放cluster中的数据,可以有多个)和mysql节点(存放表结构,可以有多个)。Cluster中的某计算机可以是某一种节点,也可以是2种或3种节点的集合。这3种节点只是在逻辑上划分,所以他们不一定和物理计算机是一一对应的关系。多个节点之间可以分布在不同的地理位置,因此也是一个实现分布式数据库的方案。
Mysql集群的出现很好的实现了数据库的负载均衡,减少了数据中心节点的压力和大数据处理,当数据库中心节点出现故障时,集群会采用一定的策略切换到其他备份节点上,有效的屏蔽了故障问题,单节点的失效不会影响整个数据库对外提供服务。而且通过采用数据库集群架构,主从数据库之间时刻都在进行数据的同步冗余,数据库是多点的、分布式的,良好的完成了数据库数据的备份,避免了数据损失。




