 Oracle-OCP学习笔记:日志原理
Oracle-OCP学习笔记:日志原理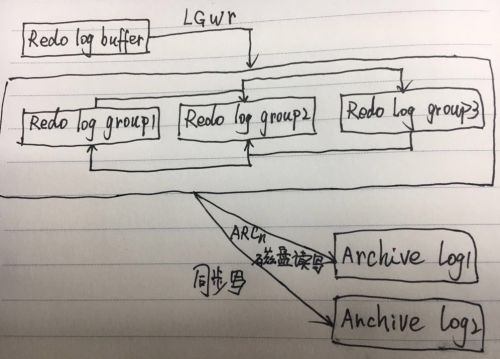
简单来说,学习Oracle数据库就两个目标:
保证数据库数据的一致性;(绝对不能出问题)
提高数据库的性能(这个和日志没关系)。
读缓存:数据从磁盘上读到内存中,CPU可以读内存中的数据,但CPU执行写时,不会写内存中的数据,要写磁盘上的数据。读缓存只能提高读的性能,对写性能不能提高
写缓存:oracle的buffer cache实现了写缓存。写缓存通过日志来实现.
存储的buffer也支持写缓存(通过电池供电)
磁盘上的缓存只提供读缓存
文件系统只提供读缓存
日志与数据库性能关系不大,但和数据的一致性关系很大
日志的功能:
只是保证数据库数据的一致性;
实现事务的快速提交
1、Oracle日志原理:日志记录数据块的所有改变
史记讲解法
日志记录方式
2、实际日志产生过程
有这样一个人,因在一个时间段内,buffer cache内有大量的buffer被修改,这个人并严格按照时间的顺序,记录buffer变更的过程,先记录到PGA中,再记录到log buffer中,再通过后台进程LOGWR,将log buffer里面的内容写到redo log日志文件中。这个人就是日志的记录过程。
日志里面记录的是:严格按照时间的顺序,记录buffer cache中每个buffer改变的过程。
Server process修改buffer cache中的buffer,这时会产生日志,这个日志变更记录先记录到PGA中,在一些触发条件下,将PGA中的变更日志写入log buffer中,当log buffer满了后,会将这些日志记录到redo log日志文件中。
日志记录的内容:
1. 记录buffer块的地址
2. 时间点
3. 对这个buffer做了什么改变(增加或删除数据,更新数据时,记录两条数据,一条删除, 一条增加)
日志产生量非常大,有可能更新一条记录,产生大量的日志
3、归档模式
alter database archivelog
ARCHIVE LOG LIST
SELECT log_mode FROM v$database
alter database noarchivelog
ALTER SYSTEM ARCHIVE LOG CURRENT #手动切换日志
ALTER SYSTEM SWITCH LOGIFLE #强行将当前日志切换到下一个日志组,不管当前日志是否写满
ALTER SYSTEM ARCHIVE LOG ALL
ALTER SYSTEM SET LOG_ARCHIVE_MAX_PROCESSES=3;
alter system set log_archive_dest ='/u01/app/oracle/archivelog1' scope = spfile;
alter system set log_archive_duplex_dest ='/u01/app/oracle/archivelog2' scope = spfile;
alter system set log_archive_dest_1 ='LOCATION=/u01/app/oracle/archivelog3';
alter system set log_archive_dest_2 = 'SERVICE=standby1';
alter system set log_archive_format ='arch_%t_%s_%r.arc';
col dest_name format a20;
col destination format a30;
selectdest_name,status,archiver,destination,log_sequence,reopen_secs,transmit_mode,process
from v$archive_dest;
selectname,sequence#,registrar,standby_dest,archived,status from v$archived_log;
v$archived_log -->从控制文件中获得归档的相关信息
v$archive_dest -->归档路径及状态
v$log_history -->控制文件中日志的历史信息
v$database -->查看数据库是否处于归档状态
v$archive_processes -->归档相关的后台进程信息
select * from v$logfile;
select member,bytes/1024/1024 from v$log a,v$logfile b
where a.group#=b.group#
select NAME,STATUS from v$archived_log;
4、如何确保已经提交的事务不会丢失
事务:一条或多条DML语句执行过程。一个事务的开始和结束是在两个commit之间。
所有已提交的事务不会丢失。
一个session,执行了sql语句,会修改buffer cache中的buffer,并产生许多日志。这些日志会写入先写到PGA中,再写到log buffer中,当log buffer满了,会快速写入到redo log磁盘文件中。
当执行commit时,buffer cache中的被修改过的buffer不会写入磁盘中的DBF文件中,而会触发后台进程logwriter将log buffer中的日志顺序写入redo log文件中。
5、Write-ahead-Log:日志写入优先
6、LGWR绕过OS缓存直接写入磁盘,但是绕不过存储的写缓存
数据从磁盘读到内存的过程:
硬盘(读缓存)->存储(写缓存,读缓存)->文件系统(读缓存)->内存中
数据从内存到磁盘文件的过程:
内存中的数据->logwriter(将log buffer写入到redo log文件中)->绕过文件系统缓存->直接写到存储的写缓存中。当写到存储的缓存中后,就会返回数据写完的信息,这个logwriter就认为数据已写到磁盘中了,但实际上,文件并没有写到磁盘中,而是存在存储的写缓存中。
7、Log buffer大小设置
9i以前,一般是3M
在10g中ORACLE会自动调整它的值,他遵循这样一个原则,'Fixed SGA Size'+ 'Redo Buffers'是granulesize(粒度) 的整数倍
SYS AS SYSDBA@ORCL>select * from v$sgainfo where namein ('Fixed SGA Size','Redo Buffers','Granule Size');
NAME BYTES RESIZEABL
-------------------- ---------- ---------
Fixed SGA Size 1336960 No
Redo Buffers 6094848 No
Granule Size 4194304 No #4M
Granule 粒度:在SGA中,将内存块划分为以粒度为单位的最小分配单位,空间的分配以这个粒度的整数倍为条件.
--在10.2.0.3 中Log Buffer 默认值是14M,在10.2.0.4中,默认值是15M
select * from v$version where rownum<2;
查看日志的组:
SYS AS SYSDBA@ORCL>select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME NEXT_CHANGE# NEXT_TIME
---------- ---------- ---------- -------------------- ---------- --------- ---------- ------------- ------------------------ ------------
1 1 170 52428800 512 1 YES INACTIVE 3386653 19-8月 -18 3414747 28-8月-18
2 1 171 52428800 512 2 YES INACTIVE 3414747 28-8月 -18 3462789 02-9月-18
3 1 173 52428800 512 1 NO CURRENT 3467124 06-9月 -18 2.8147E+14
4 1 172 10485760 512 1 YES INACTIVE 3462789 02-9月 -18 3467124 06-9月-18
Elapsed: 00:00:00.00
查看日志组:
SYS AS SYSDBA@ORCL>select * from v$logfile;
GROUP# STATUS TYPE MEMBER IS_RECOVE
---------- ---------- ---------------------------------------------------------------------- ---------
3 ONLINE /u01/app/oracle/oradata/ORCL/redo03.log NO
2 ONLINE /u01/app/oracle/oradata/ORCL/redo02.log NO
1 ONLINE /u01/app/oracle/oradata/ORCL/redo01.log NO
2 ONLINE /u01/app/oracle/oradata/ORCL/redo02_1.log NO
4 ONLINE /u01/app/oracle/oradata/ORCL/redo04.log NO
8、LGWR触发条件:Write-Ahead-Log:日志写入优先
Buffer cache将脏块写入磁盘前,要将脏块对应的变更日志先写到磁盘上。
1.用户提交
2.有1/3重做日志缓冲区未被写入磁盘
3.有大于1M的重做日志缓冲区未被写入磁盘
4.每隔3秒钟
5.DBWR需要写入的数据的SCN大于LGWR记录的SCN,DBWR触发LGWR写入
(意思是:在DBWR将脏块写入到磁盘前,会先触发lgwr将log buffer的日志写入到redo log中,也就是日志总是先于buffer写入到磁盘上)
9、LOG优化建议
在OLTP 系统上,REDO LOG 文件的写操作主要是小型的,比较频繁,一般的写大小在几K,而每秒钟产生的写IO 次数会达到几十次,数百次甚至上千次。因此REDO LOG文件适合存放于IOPS 较高的转速较快的磁盘上,IOPS 仅能达到数百次的SATA 盘不适合存放REDO LOG 文件。另外由于REDO LOG 文件的写入是串行的,因此对于REDO LOG文件所做的底层条带化处理,对于REDO LOG 写性能的提升是十分有限的。
Redo log 日志不要放在raid5,6的磁盘阵列上,可以放到固态盘或RAID10 或RAID01上面。
10、REDO LOG 切换的时间应该尽可能的不低于10-20 分钟, 也就是一个日志文件从开始写到这个日志写满需要切换到下一个日志文件之前,这段写的时间在约为10-20分钟以内。
通过当前的产生日志的速度,可以调整日志文件的大小来控制。
查看日志切换的时间:
select to_char(FIRST_TIME,'yyyy-mm-dd hh24:mi:ss')f_time,SEQUENCE# from v$log_history order by f_time desc;
11、日志相关的一些操作
alter database add logfile group 5'/opt/oracle/oradata/dbtest/redo05_1.log' SIZE 10M
alter database add logfile member'/opt/oracle/oradata/dbtest/redo04_3.log' to group 4
alter database drop logfile group 5
alter database drop logfile ('/opt/oracle/oradata/dbtest/redo05_1.log','/opt/oracle/oradata/dbtest/redo05_2.log')




