 Oracle-OCP学习笔记:检查点队列
Oracle-OCP学习笔记:检查点队列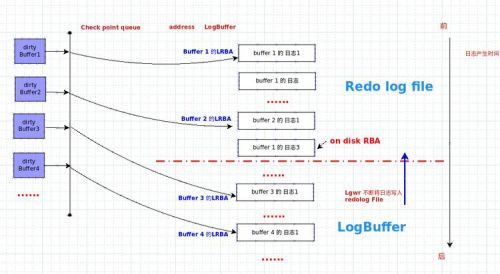
1、检查点队列 checkpoint queue chain(按LRBA地址连接起来的)
LRU:干净块
LRUW:脏块
CBC:按地址
Checkpoint queue chain:脏块链,接块的访问频率来分,分为冷端和热端
RBA 日志块地址 (redo block address)
LRBA(Low RBA) 第一次被脏的日志块地址 #每一个块都有一个LRBA,一个HRBA地址
HRBA 最近一次被脏的日志块地址
on disk rba 重做日志(current redo log)中最后一条日志的地址
数据块里有两个地址,LRBA,HRBA.
checkpoint queue 按照脏块第一次脏的时间链起来。
checkpoint queue 就是按照数据块的LRBA地址链起来的。
2、CKPT进程(检查点进程)
每隔3秒钟触发一次
记录检查点信息
触发DBWR进程
CKPT两种工作方式:
1.完全检查点:会触发将所有脏块写入磁盘。
只有正常关闭的时候才会发生完全检查点。正常运行期间基本不会发生完全检查点。
2.增量检查点:ckpt会将检查点队列的第一个最早脏的数据块所对应的(LRBA)日志地址记录到控制文件中。增量检查点每隔3秒钟会发生一次。
当增量检查点发生时,ckpt会将检查点队列的第一块最早脏的,所对应的日志地址记录到控制文件中。当增量检查点发生时,发现checkpoint queue太长,I/O也不太忙的话,会触发DBWn,部分写到磁盘上,以缩短checkpoint queue的长度。
DBWn进程触发的条件:
1.DBWn写,根据LRUW写
2.checkpoint queue 很长的时候,也会适当的触发DBWn写。
On disk RBA:是current块生成的日志的最后一条日志的物理地址,也就是目前数据库所保存的最后一条日志的地址。
Low RBA检查点队列记录最开始脏的块的日志的地址。
3、增量检查点并不会去更新数据文件头,以及控制文件中数据库SCN以及数据文件条目的SCN信息,而只是每3秒由CKPT进程去更新控制文件中的lowcache rba信息,也就是检查点的位置。
select CPDRT,CPLRBA_SEQ||'.'||CPLRBA_BNO||'.'||CPLRBA_BOF"LowRBA",CPODR_SEQ||'.'||CPODR_BNO||'.'||CPODR_BOF "On diskRBA",CPODS,CPODT,CPHBT from x$kcccp;

CPDRT列是检查点队列中的脏块数目.
CPODS列是on disk rba的scn, (ondisk rba对应的SCN号)
CPODT列是on disk rba的时间戳
CPHBT列是心跳
如 果发生了实例崩溃,只需要在日志文件中找到检查点位置(low cacherba),从此处开始应用所有的重做日志文件,就完成了前滚操作。实例崩溃后,再次启动数据库,oracle会到控制文件中读取low cache rba,这就是检查点位置。从此处开始应用重做日志,应用到ondisk rba的位置。on disk rba是磁盘中重做日志文件的最后一条重做记录的rba。
相关操作:
select checkpoint_change# from v$database;
alter system checkpoint;
alter system switch logfile;
select name,checkpoint_change# from v$datafile ;
select name,checkpoint_change# from v$datafile_header;
select * from v$log;
create table t2(id int, name varchar2(50));
begin
for i in 1..10000 loop
insert into t2 values(1,'xkj');
commit;
end loop;
end;
select * from t2; |
alter system flush buffer_cache; #将所有脏块清到磁盘上
----------------------------------------------------
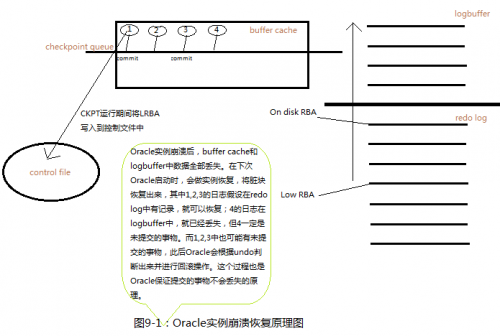
实例崩溃恢复原理分析:
正常运行的数据库突然死机,在内存中被修改的buffer cache还没有写入磁盘,就有可能出现数据丢失的情况。
如果是未提交的事务修改的数据块可以丢失
已提交事务所对应的数据脏块不能丢失,因为已提交的事务日志已写到logbuffer,但在buffer cache中,脏块本身还没有写入磁盘中。
丢失的脏块可以通过日志找回来。Oracle可以通过redo log日志来构造脏块。
一部分日志在log buffer中,一部分日志在redo log
在redo log中的日志对应的事务一定提交了。
如果log buffer中有日志,则说明日志所对应的事务还没有提交,数据可以丢失。
找到redo log 日志的起点与终点:
终点:current日志文件的最后一条日志
起点:在控制文件中,通过检查点队列的LRBA地址找到redo log日志的起点。应用redo log起点以前的日志,一直到current日志为止,构造buffer cache中丢失的日志。
如果实例崩溃,要恢复时,oracle会通过redo log日志来恢复buffer cache中的脏块,通过检查点对列对应写入控制文件中的LRBA地址找到redo log日志的起点,再结合current日志做为终点。完成日志的前滚操作。恢复到buffer cache中,还存在未提交的事务,再通过undo log来回滚未提交的事务。到这时,oracle就完成了实例的恢复。
select CPDRT,CPLRBA_SEQ||'.'||CPLRBA_BNO||'.'||CPLRBA_BOF"LowRBA",CPODR_SEQ||'.'||CPODR_BNO||'.'||CPODR_BOF "On diskRBA",CPODS,CPODT,CPHBT from x$kcccp;

以上图表示,如果实例崩溃后,需要跑的日志为从LowRBA到on disk RBA之间的日志
检查点队列的意义:找到跑日志的起点,加快实例崩溃后oracle的启动速度。oracle 8之前,没有检查点队列,确定不了日志的起点,要跑很多日志,启动速度很慢。




