 Oracle-OCPѧϰ�ʼ�:�ַ���
Oracle-OCPѧϰ�ʼ�:�ַ���linux�������ַ�����
[root@single ~]# locale
LANG=en_US.UTF-8
LC_CTYPE="en_US.UTF-8"
#export NLS_LANG=american_america.zhs16gbk
windows�������ַ�����
C:\Users\Martin>chcp
�����ҳ: 936
C:>set NLS_LANG=american_america.zhs16gbk
�ַ������ࣺ
����ϵͳ�ַ���
Oracle�����ַ���
Sql developer�������ַ������������û���ַ�������ʹ�ò���ϵͳ�ַ���
SYS AS SYSDBA@ORCL>desc t2;
Name Null? Type
ID NUMBER(38)
NAME VARCHAR2(20)
ID���������У�����Ҫʹ���ַ���
NAME����VARCHAR2������Ҫʹ���ַ�����ת����
�ַ��������úͺ��壺
�ַ�����
ʹ�ó���
���ݿ��ַ���,��������Ҫʹ���ַ�����
1. �����洢CHAR,VARCHAR2,CLOB,LONG����������
2. ������ʾ��������������Լ�PL/SQL������
3. �����洢SQL��PL/SQL����Ԫ��
�����ַ�����
�����洢NCHAR,NVARCHAR2,NCLOB����������,���û����Щ���͵����ݣ�����Ҫʹ�ù����ַ�����
SYS ASSYSDBA@ORCL>desc t3;
Name Null? Type
-----------------------------------------------------------------------------------
ID NUMBER
NAME NVARCHAR2(20)
�ͻ���OS�ַ�����NLS_LANG���ã������OS�ַ�����ORACLE���ݿ��ַ���
�ַ���֮��Ĺ�ϵ
��ȷ�����ַ���
�ַ������������Ժ���ж�����
�洢���Ǵ�����ַ���
�洢�ǵ���ȷ���ַ���
Locale locale �Ca,chcp
�ַ�����ʵ���ǡ��ַ����͡����롱��һ�Ŷ��ձ�
�ַ���ԭ����
�ַ�������һ�����������У�
��ߵ�����Ҫ�洢���ַ������������ַ�����ʤ����
�ұߵ�����һ�����룬Ҳ���Ǽ��������洢�����֡���Ϊ���������ֻ�ܴ洢���֣����ܴ洢�ַ���
�����ַ������������ܿ������ַ����ַ���Ӧ�ı���Ķ�Ӧ����
�ַ���������
ORACLE���ַ���������ѭ������������
<Language><bit size><encoding>
����<����><�����><����>
���磺ZHS16GBK��ʾ����GBK�����ʽ��16λ�������ֽڣ������������ַ���
US7ASCII #ֻ�ܴ洢������ʹ�õ��ַ���26����ĸ,���֣��������(+-*/),����������128���ַ�
ZHS16CGB231280 #�����ַ������ǹ��꣬�Ƚ�����
ZHS16GBK #���µ������ַ���,���ַ���Zhs16CGB231280�ij���,�����ϸ�
AF16UTF16#�����ַ���
unicode�ַ�����
AL32UTF8 #���µ�UTF8�ַ���(��������ҵ�����������ַ���Ҳ���������ҵ��ַ�)
UTF8 #�Ƚ��ϣ��ַ�����ȫ��
ע��ʵ���������������ȷ�����ݿ�ֻ���й����ã�ֻ����Ӣ������ַ����Ļ����Ͳ���ZHS16GBK..
���ݿⰲװ�����У���ѡ��ȷ�����������ַ�����
1.���ݿ��ַ��������ݿ���Ҫ�洢�������ѡ��AL32UTF8��ֻ����Ӣ��ѡ��ZHS16GBK
2.�����ַ��� һ�㶼ѡ��AL16UTF16
NLS_LANG=<language>_<territory>.<clientcharacter set>
Language:��ʾoracle��Ϣ��У�飬��������,����������ʾ����Ӣ����ʾ
Territory:ָ��Ĭ�����ڣ����֣����ҵȸ�ʽ
Clientcharacter set:ָ���ͻ��˽�ʹ�õ��ַ���
���磺NLS_LANG=AMERICAN_AMERICA.US7ASCII
AMERICAN�������ԣ�AMERICA�ǵ�����US7ASCII�ǿͻ����ַ���
Oracle�ṩ����NLS�����������ݿ���û�����Ӧ���ظ�ʽ��������NLS_LANGUAGE,NLS_DATE_FORMAT,NLS_CALENDER�ȣ�����ͨ����ѯ���������ֵ��v$��ͼ�鿴��
NLS_DATABASE_PARAMETERS �C��ʾ���ݿǰNLS����ȡֵ���������ݿ��ַ���ȡֵ
NLS_SESSION_PARAMETERS -��ʾ��NLS_LANG���õIJ�������alter session�ı��IJ���ֵ(��������NLS_LANG���õĿͻ����ַ���)
NLS_INSTANCE_PARAMETE -��ʾ�ɲ����ļ�init<SID>.ora����IJ���
V$NLS_PARAMETERS -��ʾ���ݿǰNLS����ȡֵ��
�鿴���ݿ��ַ������õö�
SYS AS SYSDBA@ORCL>select * fromnls_database_parameters where PARAMETER='NLS_CHARACTERSET';
PARAMETER VALUE
NLS_CHARACTERSET AL32UTF8
�鿴�����ַ������õ��٣���Ϊ���ݿ��ַ����IJ���
SYS AS SYSDBA@ORCL>select * fromnls_database_parameters where PARAMETER='NLS_NCHAR_CHARACTERSET';
PARAMETER VALUE
NLS_NCHAR_CHARACTERSET UTF8
�鿴��ǰsessionʹ�õ��ַ�����
SYS AS SYSDBA@ORCL>select * from nls_session_parameters;
SYS AS SYSDBA@ORCL>select userenv('language') fromdual;
USERENV('LANGUAGE')
-------------------------------------------------
SIMPLIFIED CHINESE_CHINA.AL32UTF8
SYS AS SYSDBA@ORCL>select nls_charset_name(to_number('0354','xxxx'))from dual;
NLS_CHARSET_NAME(TO_NUMBER('0354','XXXX'))
----------------------------------------------
ZHS16GBK
SYS AS SYSDBA@ORCL>! echo $NLS_LANG
SIMPLIFIED CHINESE_CHINA.UTF8
SYS AS SYSDBA@ORCL>select to_char(nls_charset_id('ZHS16GBK'),'xxxx')from dual;
TO_CHAR(NLS_CHARSET_ID('ZHS16GBK'),'XXXX')
------------------------------------------------------------------------------------------------------------------------------------------------------
354
�鿴ϵͳ֧�ֵ��ַ�����
SYS AS SYSDBA@ORCL>select * from V$NLS_VALID_VALUES;
sql*plus�ͻ���������ԭ�������ڲ���ϵͳ�ַ���һ����:
sqlplus û���ַ����������ò���ϵͳ�ַ���
sqldeveloper ����������ַ��������в��ò���ϵͳ�ַ���
oracle���ַ���������oracle���ò���ϵͳ�ַ���
�ܽ������oracle client������ַ������������ַ���Ϊ���������ò���ϵͳ���ַ���,�����ַ�����ת������oracle�ڲ���ɵġ�
�ͻ����ַ������ã�(ͨ�����ÿͻ����ַ�����oracle��֪���ͻ�����ʲô�ַ������롣)
windows��һ�㶼��gbk����chcp���Ϊ936
c:>set NLS_LANG=american_america.zhs16gbk
���Ժ͵���Ϊ�����й��Ļ���set NLS_LANG=simplifiedchinese_china.zhs16gbk
linux��һ��Ϊutf-8����echo $LANG ���Ϊen_US.UTF-8 ��zh_CN.UTF-8
#export NLS_LANG=american_america.utf8
�����Ǵ�����ַ������ã�
ԭ�ͻ��˵�NLS_LANG���õ��ַ���Ҫ��ͻ���������ͻ��˲���ϵͳ���ַ���Ҫһ��
ORACLE�����Ǵ����ݻ���ȡ���ݣ���Ҫ��ͻ���ѯ�ʣ��Է��������ı�����ͨ��ʲô�ַ���ת���ġ�
������ݿ��ַ�����ͻ��˵��ַ���һ����ORACLE���ᷢ���ַ���ת����
������ݿ��ַ�����ͻ��˵��ַ�����һ����ORACLE�ᷢ�������ת����
����ͼ�Ŀͻ����ַ�����NLS_LANG�ַ�����һ�������Ǵ���ģ�������������NLS_LANG�ַ���Ҫ���ó���ͻ��˷�������ͻ����������ַ���һ����
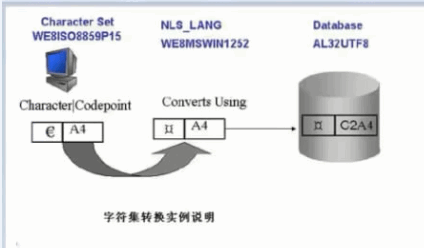
��ͼ�����ԭ��
�ͻ�����varchar2�����͵����ϴ�һ���ַ�����ʱ�ڿͻ��˻Ὣ�ַ�ת���ɱ���A4����ʱ�����A4���͵�ORACLE����ˣ���ʱORACLE�ͻ��ʣ����A4��������ʲô�ַ�������ģ���Ϊ��ʱ�ͻ��˵�NLS_LANG�ַ���ΪWE8MSWIN1252������oracle����Ϊ�ͻ��˵��ַ���ΪWE8MSWIN1252,������ʵ�ʵ�WE8ISO8859P15����ʱoracle����һ�����ݿ���ַ�����AL32UTF8,��ͻ��˵��ַ���WE8MSWIN1252,����ORACLE���Ƚ�A4���������WE8MSWIN1252�ַ���ת����A4��Ӧ���ַ����ٽ��ַ�ͨ��AL32UTF8ת���ɱ���C2A4��ORACLE��ֱ�Ӵ����ת���õı���C2A4��
���ͻ��˶�ȡ���ݿ���ַ�ʱ��ORACLE������AL32UTF8�ַ�����Ӧ�ı���C2A4,ORACLE�鿴��NLS_LANG���ַ���ΪWE8MSWIN1252,�����ݿ���ַ�����һ��������ORACLE�ὫC2A4��ͨ��AL32UTF8ת��Ϊ�ַ�����������ַ�ͨ��WE8MSWIN1252ת���ɱ��롣��ʱ�ͻ��˿����ľ���������룬����ʱͨ��WE8ISO8859P15�ַ��������������ʱ�ò���ԭ�����ַ�����ʱ���ַ��Ͳ��������롣
��ͼ��NLS_LANG�ַ��������ݿ���ַ���һ������ͻ��˵��ַ�����һ����
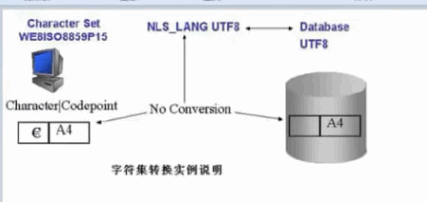
��ͼ�����ԭ��
�ͻ��˽��ַ������õ�A4���룬��ʱ�ͻ���NLS_LANG����ΪUTF8,�����ݿ���ַ���Ҳ��UTF8,���Ե���������봫�����ݿ�ʱ��ORACLE�����ͻ��˵�NLS_LANG���ַ��������ݿ���ַ���һ��������oracle����ת��������ֱ�ӽ�����A4�������ݿ⡣
���ԣ�
�ͻ���Linux��ϵͳ�ַ���Ϊzh_CN.UTF-8
��ȷ���ã�
#export LANG=zh_CN.UTF-8
#export NLS_LANG=american_america.utf8
[oracle@oracle ~]$ echo $NLS_LANG
american_america.utf8
[oracle@oracle ~]$ echo $LANG
zh_CN.UTF-8
SYS AS SYSDBA@ORCL>select * from t3;
ID NAME
---------- --------------------
1 ��ʤ��
commit;
�鿴�ַ���Ӧ�ı��룺����������oracle�洢�����ġ�
SYS AS SYSDBA@ORCL>select id,name,dump(name,1016) fromt3;
ID NAME
---------- --------------------
DUMP(NAME,1016)
------------------------------------------------------------------------------------------------------------------------------------------------------
1 ��ʤ��
Typ=1 Len=9 CharacterSet=UTF8: e9,98,ae,e8,83,9c,e6,98,8c #��16������ʾ
select id,name,dump(name,1010) from t3; #��10������ʾ
Typ=1 Len=9 CharacterSet=UTF8:233,152,174,232,131,156,230,152,140
select id,name,dump(name,1008) from t3; #��8������ʾ
Typ=1 Len=9 CharacterSet=UTF8:351,230,256,350,203,234,346,230,214
��������1��
[oracle@oracle ~]$ echo $LANG
en_US.UTF-8
[oracle@oracle ~]$ echo $NLS_LANG
SIMPLIFIED CHINESE_CHINA.UTF8
SYS AS SYSDBA@ORCL>select id,name from t3;
ID NAME
---------- --------------------
1 껨ݯ?
��������2��
#export NLS_LANG=american_america.zhs16gbk
select dump('����',1016) from dual;
insert into t2 values (2,'����');
commit;
ע�⣺�ַ������ô����¿��д洢�ľ��Ǵ���ı��룬��������Dz������`һ��Ҫ������ϸ���ú��ַ�����
�鿴�ַ�����ʤ���ַ���ȷ�ı���:
SYS AS SYSDBA@ORCL>select dump('��ʤ��',1016) from dual;
DUMP('��ʤ��',1016)
Typ=96 Len=9 CharacterSet=AL32UTF8:e9,98,ae,e8,83,9c,e6,98,8c
insert into t2 values (2,'��ʤ��');
commit;
��������oracle�ַ���
���ȷ����ǰ�ַ����趨����ʱ���Ը����ַ�����
SYS AS SYSDBA@ORCL>select userenv('language') fromdual;
USERENV('LANGUAGE')
AMERICAN_AMERICA.AL32UTF8
�鿴ϵͳ���ַ�����
select * from v$nls_parameters;
�˽ⳬ�����ϸ��ĸ��ȷ���Ƿ���Ը����ַ�����Oracle��������ڸ������ݿ��ַ�����
����������ϵͳ�ַ�������ʱ���ԣ�
ps:
1.��Ϊsql*plus ����û���ַ��������������ڲ���ϵͳ���ַ���������Զ��linux�ϵ�oracleҲ����ֱ�ӷ��ʵ�windows�ϵ��ַ�������������sql*plus��NLS_LANG���������
2.��Ϊoracle�����������ַ��������������Լ����ַ���ʱ���Ͳ��ò���ϵͳ���ַ��������Է���������ϵͳ�ַ��������ؿ�����ʱ���ԡ�




