 MySQL复合索引比主键索引还快,为什么?
MySQL复合索引比主键索引还快,为什么?存储引擎:innodb
题目如下:
create table t(
id primary,
ver int,
content varchar(3000),
intro varchar(3000)
) engine innodb charset utf8;
表有10000条数据,按如下条件查询:
select id from t order by id #慢
select id from t order by id,ver #快
为什么?
实验如下:
创建一个innodb引擎的表:
create table smth(
id int(11) not null default '0',
ver int(11) default null,
content varchar(3000) default null,
intro varchar(3000) default null,
primary key(id),
key idver(id,ver)
)engine=innodb default charset=utf8;
通过php批量插入10000条数据:
input.php
<?php
set_time_limit(0);
$conn=mysql_connect('192.168.1.100','root','');
mysql_query('set names utf8',$conn)
mysql_query('use myopt',$conn);
for ($i=1;$i<=10000;$i++){
$sql=sprintf("insert into smth values(%d,%d,'%s','%s')",$i,rand(1,1000),str_repeat('中',3000),str_repeat('华',3000));
mysql_query($sql,$conn);
}
echo 'successfull';
?>
插入的数据如下图
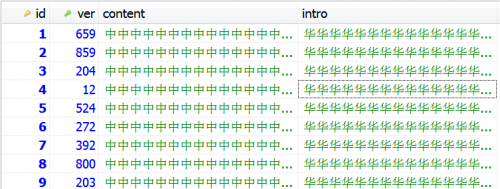
mysql> use myopt;
Database changed
mysql> show tables;
+-----------------+
| Tables_in_myopt |
+-----------------+
| smth |
+-----------------+
1 row in set (0.00 sec)
mysql> select count(*) from smth;
+----------+
| count(*) |
+----------+
| 10000 |
+----------+
1 row in set (0.00 sec)
smth表已有10000条数据
打开profiling:
mysql> set profiling=1;
运行以下两条SQL语句:
select id from smth order by id #慢
select id from smth order by id,ver #快
查看两条SQL语句执行的时间:
mysql> show profiles;
+----------+------------+-------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+-------------------------------------+
| 1 |0.57919600 | select id from smth order by id | #慢
| 2 |0.00014700 | select id from smth order by id ver | #快
+----------+------------+-------------------------------------+
3 rows in set (0.00 sec)
两条语句的时间差了好几个数据级,这是为什么呢?
下面分析原因:
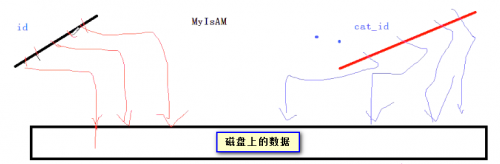
INNODB引擎,如果ID为主键,则会创建一个基于主键的聚簇索引,这个索引是以下面的形式而存在
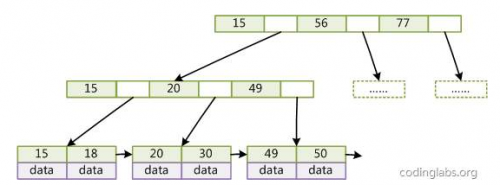
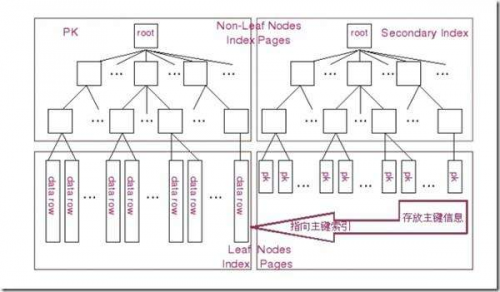
innodb的索引下面就包含具体的表数据,找到了索引,就找到的具体的数据
但由于表中有两个大的字段varchar(30000),使得索引键值下面的数据太大,有可能一个索引键值对应一个数据页(16K)或多个数据页。这使得查询一个ID值将要扫描更多的数据页,才能取出ID值。
如下图:这个就是SQL语句select id from smthorder by id的情况。
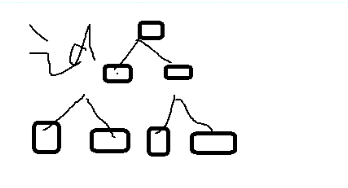
对于select id from smth order by id ver的分析:
对ID,VER两个字段创建索引,返回ID的值,也就是说可以直接通过覆盖索引就可以找到所要的数据,不需要再回表查主键对应的数据,相当于在索引查数据,所有速度比上面的那个SQL要快
如下图:

如果存储引擎换成:MyISAM,结果会怎么样呢?
MYISAM索引的结构:
题目如下:
create table t(
id primary,
ver int,
content varchar(3000),
intro varchar(3000)
) engine innodb charset utf8;
表有10000条数据,按如下条件查询:
select id from t order by id
select id from t order by id,ver
为什么?
创建一个myisam引擎的表:
create table mysmth(
id int(11) not null default '0',
ver int(11) default null,
content varchar(3000) default null,
intro varchar(3000) default null,
primary key(id),
key idver(id,ver)
)engine=myisam default charset=utf8;
复制smth的数据到mysmth:
mysql> insert into mysmth select * from smth;
Query OK, 10000 rows affected (13.22 sec)
Records: 10000 Duplicates: 0 Warnings: 0
mysql> show tables;
+-----------------+
| Tables_in_myopt |
+-----------------+
| mysmth |
| smth |
+-----------------+
2 rows in set (0.00 sec)
mysql> select count(*) from mysmth;
+----------+
| count(*) |
+----------+
| 10000 |
+----------+
1 row in set (0.00 sec)
插入的数据如下:
实验测试:
打开profiling:
mysql> set profiling=1;
运行以下两条SQL语句:
select id from mysmth order by id
select id from mysmth order by id,ver
查看两条SQL语句执行的时间:
mysql> show profiles;
mysql> show profiles;
+----------+-------------+---------------------------------------+
| Query_ID | Duration | Query |
+----------+-------------+---------------------------------------+
| 10 | 0.00500125 |select id from mysmth order by id | #时间基本一样
| 11 | 0.00676950 |select id from mysmth order by id,ver | #时间基本一样
+----------+-------------+---------------------------------------+
2 rows in set (0.00 sec)
为什么?
这是因为myisam引擎中的索引与数据是分开的,索引的多少与数据不存在任何关联,由于是查询ID值,而且都是通过索引覆盖扫描,并没有找真正的数据,所有查询时间差不多
总结:
以上是由于存储引擎的特性决定了同一条SQL不同的执行时间




