 Oracle Data Guard环境搭建,看这篇就够了
Oracle Data Guard环境搭建,看这篇就够了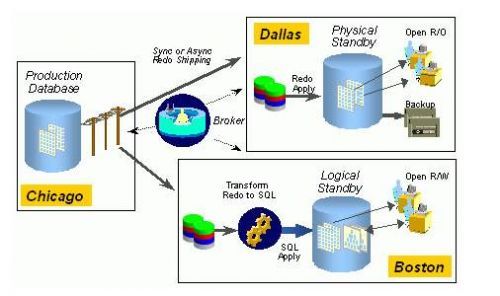
配置中如果有问题,请一定要查看备库的警告日志文件
tail -f /u01/app/oracle/diag/rdbms/ora11g_standby/orcl/trace/alert_orcl.log
操作系统环境:
[oracle@node139 dbs]$ uname -a
Linux node139 4.1.12-61.1.28.el6uek.x86_64 #2 SMP Thu Feb 23 20:03:53 PST 2017 x86_64 x86_64 x86_64 GNU/Linux
[oracle@node139 dbs]$ cat /etc/redhat-release
Red Hat Enterprise Linux Server release 6.9 (Santiago)
Primary数据库:
IP 地址:172.16.1.139
数据库SID:orcl
GLOBAL_DBNAME= orcl
DB_UNIQUE_NAME:ora11g_primary
SERVICE_NAME = ora11g_primary
Standby数据库:
IP 地址:172.16.1.140
数据库SID:orcl
GLOBAL_DBNAME= orcl
DB_UNIQUE_NAME:ora11g_standby
SERVICE_NAME = ora11g_standby
(注:oracle数据库版本是11.2.0.4.0)
1.Primary端的配置
(1).检查数据库是否支持 Data Guard(企业版才支持),是否归档模式,Enable force logging
$ sqlplus '/as sysdba'
SQL> select * from v$option where parameter = 'Managed Standby';
确认主库处于归档模式
SQL> archive log list (先检查是否归档模式,不是则修改)
startup mount
alter database archivelog;
alter database open;
(2)将primary 数据库置为 FORCE LOGGING模式
SQL> alter database force logging; (强制产生日志)
如果主库没有密码文件则建立密码文件,从而可以 OS验证的方式登陆
$ orapwd file=$ORACLE_HOME/dbs/orapworcl password=123456 entries=5
(3)为主数据库添加备用联机日志文件
SQL>
alter database add standby logfile group 4 ('/u01/app/oracle/oradata/orcl/stdby_redo04.log') size 50m;
alter database add standby logfile group 5 ('/u01/app/oracle/oradata/orcl/stdby_redo05.log') size 50m;
alter database add standby logfile group 6 ('/u01/app/oracle/oradata/orcl/stdby_redo06.log') size 50m;
alter database add standby logfile group 7 ('/u01/app/oracle/oradata/orcl/stdby_redo07.log') size 50m;
standby redolog的组数参考公式:(online redolog组数 + 1) * 数据库线程数;单机线程数为1,RAC一般为2。
standby redolog的组成员数和大小也尽量和online redolog一样。
(注:在备库中也要建立相同的standbylog组)
后面将所有的日志复制到备库
(4)修改主库参数文件
SQL> create pfile='/home/oracle/pfile.ora' from spfile;
主库
cat /home/oracle/pfile.ora
orcl.__db_cache_size=184549376
orcl.__java_pool_size=4194304
orcl.__large_pool_size=8388608
orcl.__oracle_base='/u01/app/oracle'#ORACLE_BASE set from environment
orcl.__pga_aggregate_target=155189248
orcl.__sga_target=331350016
orcl.__shared_io_pool_size=0
orcl.__shared_pool_size=125829120
orcl.__streams_pool_size=0
*.audit_file_dest='/u01/app/oracle/admin/orcl/adump'
*.audit_trail='db'
*.compatible='11.2.0.4.0'
*.control_files='/u01/app/oracle/oradata/orcl/control01.ctl','/u01/app/oracle/fast_recovery_area/orcl/control02.ctl'
*.db_block_size=8192
*.db_domain=''
*.db_name='orcl'
*.db_recovery_file_dest='/u01/app/oracle/fast_recovery_area'
*.db_recovery_file_dest_size=4385144832
*.diagnostic_dest='/u01/app/oracle'
*.dispatchers='(PROTOCOL=TCP) (SERVICE=orclXDB)'
*.log_archive_format='%t_%s_%r.dbf'
*.memory_target=484442112
*.open_cursors=300
*.processes=300
*.remote_login_passwordfile='EXCLUSIVE'
*.sessions=335
*.undo_tablespace='UNDOTBS1'
*.db_unique_name='ora11g_primary'
*.log_archive_config='DG_CONFIG=(ora11g_primary, ora11g_standby)'
*.log_archive_dest_1='location=/u01/app/oracle/archive VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=ora11g_primary'
*.log_archive_dest_2='SERVICE=ora11g_standby LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=ora11g_standby'
*.log_archive_dest_state_1='ENABLE'
*.log_archive_dest_state_2='ENABLE'
*.standby_file_management='AUTO'
*.fal_client='ora11g_primary'
*.fal_server='ora11g_standby'
(5)在主库上建立备用库用的控制文件
SQL>shutdown immediate
SQL>startup mount
SQL> alter database create standby controlfile as '/u01/standby_ctl01.ctl';
(6)配置listener.ora和tnsnames.ora
Listener.ora 文件:
# listener.ora Network Configuration File: /u01/app/oracle/product/11.2.0.4/dbhome_1/network/admin/listener.ora
# Generated by Oracle configuration tools.
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = PLSExtProc)
(ORACLE_HOME = /u01/app/oracle/product/11.2.0.4/dbhome_1)
(PROGRAM = extproc)
)
(SID_DESC =
(GLOBAL_DBNAME= orcl)
(ORACLE_HOME = /u01/app/oracle/product/11.2.0.4/dbhome_1)
(SID_NAME = orcl)
)
)
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = node139)(PORT = 1521))
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521))
)
)
ADR_BASE_LISTENER = /u01/app/oracle
tnsnames.ora文件:
# tnsnames.ora Network Configuration File: /u01/app/oracle/product/11.2.0.4/dbhome_1/network/admin/tnsnames.ora
# Generated by Oracle configuration tools.
ORA11G_PRIMARY =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = node139)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ora11g_primary)
)
)
ORA11G_STANDBY =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = node140)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ora11g_standby)
)
)
(7)主库用修改过的PFIL文件导入SPFILE环境中
关闭主数据库
SQL>shutdown immediate
生成spfile
SQL> create spfilefrom pfile=='/home/oracle/pfile.ora' ;
2.Standby端的配置
(1). 创建备库存放数据文件和后台跟踪目录
mkdir -p $ORACLE_BASE/oradata/orcl
mkdir -p $ORACLE_BASE/admin/orcl
mkdir -p $ORACLE_BASE/admin/orcl/adump
mkdir -p $ORACLE_BASE/admin/orcl/bdump
mkdir -p $ORACLE_BASE/admin/orcl/cdump
mkdir -p $ORACLE_BASE/admin/orcl/dpdump
mkdir -p $ORACLE_BASE/admin/orcl/pfile
mkdir -p $ORACLE_BASE/admin/orcl/udump
mkdir -p $ORACLE_BASE/diag/rdbms
mkdir -p $ORACLE_BASE/diag/tnslsnr
mkdir -p $ORACLE_BASE/flash_recovery_area/orcl
mkdir -p $ORACLE_BASE/flash_recovery_area/ORCL
mkdir -p $ORACLE_BASE/archive
(2).把文件传输到备库下
关闭主库复制文件
$scp $ORACLE_BASE/oradata/*.dbf 172.16.1.140:/$ORACLE_BASE/oradata/orcl/
$scp $ORACLE_BASE/oradata/.log 172.16.1.140:/$ORACLE_BASE/oradata/orcl/
$scp /u01/standby_ctl01.ctl 172.16.1.140:/$ORACLE_BASE/oradata/orcl/
$scp $ORACLE_HOME/dbs/* 172.16.1.140: $ORACLE_HOME/dbs/
修改控制文件名:
$ cd $ORACLE_BASE/oradata/orcl
$ mv standby_ctl01.ctl control01.ctl
$ cp control01.ctl /u01/app/oracle/fast_recovery_area/ora11g/
$cd /u01/app/oracle/fast_recovery_area/ora11g/
$ mv control01.ctl control02.ctl
(3)建立密码文件
如果主库没有密码文件则建立密码文件,从而可以 OS验证的方式登陆
$ orapwd file=$ORACLE_HOME/dbs/orapworcl password=oracle entries=5
(4)修改备库参数文件
orcl.__db_cache_size=79691776
orcl.__java_pool_size=4194304
orcl.__large_pool_size=125829120
orcl.__oracle_base='/u01/app/oracle'#ORACLE_BASE set from environment
orcl.__pga_aggregate_target=150994944
orcl.__sga_target=335544320
orcl.__shared_io_pool_size=0
orcl.__shared_pool_size=117440512
orcl.__streams_pool_size=0
*.audit_file_dest='/u01/app/oracle/admin/orcl/adump'
*.audit_trail='db'
*.compatible='11.2.0.4.0'
*.control_files='/u01/app/oracle/oradata/orcl/control01.ctl','/u01/app/oracle/fast_recovery_area/orcl/control02.ctl'
*.db_block_size=8192
*.db_domain=''
*.db_name='orcl'
*.db_recovery_file_dest='/u01/app/oracle/fast_recovery_area'
*.db_recovery_file_dest_size=4385144832
*.db_unique_name='ora11g_standby'
*.diagnostic_dest='/u01/app/oracle'
*.dispatchers='(PROTOCOL=TCP) (SERVICE=orclXDB)'
*.fal_client='ora11g_standby'
*.fal_server='ora11g_primary'
*.log_archive_config='DG_CONFIG=(ora11g_primary, ora11g_standby)'
*.log_archive_dest_1='location=/u01/app/oracle/archive VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=ora11g_standby'
*.log_archive_dest_2='SERVICE=ora11g_primary LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=ora11g_primary'
*.log_archive_dest_state_1='ENABLE'
*.log_archive_dest_state_2='ENABLE'
*.log_archive_format='%t_%s_%r.dbf'
*.memory_target=484442112
*.open_cursors=300
*.processes=300
*.remote_login_passwordfile='EXCLUSIVE'
*.sessions=335
*.standby_file_management='AUTO'
*.undo_tablespace='UNDOTBS1'
(4)修改备库的listener.ora和tnsnames.ora,如果没有的话,可以直接从主库复制过去
Listener.ora 文件:
# listener.ora Network Configuration File: /u01/app/oracle/product/11.2.0.4/dbhome_1/network/admin/listener.ora
# Generated by Oracle configuration tools.
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = PLSExtProc)
(ORACLE_HOME = /u01/app/oracle/product/11.2.0.4/dbhome_1)
(PROGRAM = extproc)
)
(SID_DESC =
(GLOBAL_DBNAME= orcl)
(ORACLE_HOME = /u01/app/oracle/product/11.2.0.4/dbhome_1)
(SID_NAME = orcl)
)
)
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = node140)(PORT = 1521))
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521))
)
)
ADR_BASE_LISTENER = /u01/app/oracle
tnsnames.ora文件:
# tnsnames.ora Network Configuration File: /u01/app/oracle/product/11.2.0.4/dbhome_1/network/admin/tnsnames.ora
# Generated by Oracle configuration tools.
ORA11G_PRIMARY =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = node139)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ora11g_primary)
)
)
ORA11G_STANDBY =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = node140)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ora11g_standby)
)
)
(5)复制主库的密码文件到备库的相应位置(注:如果主备库不能同步很可能就是密码文件不一样)
先查看备份库是否有密码文件,有就先删除,然后再复制。
scp $ORACLE_HOME/dbs/orapworcl 172.16.1.140:/$ORACLE_HOME/dbs/
3.Dataguard启动
(1)启动顺序,先启动备库,然后再启动主库
启动standby database
SQL>startup nomount
SQL>alter database mount standby database; #执行此命令后备库会处于手动恢复状态。
启动primary database
SQL>startup mount
SQL>alter database set standby database to maximize availability; (设置为最大性能模式也是默认模式)
SQL>alter database open;
启动standby database到recover manage模式
SQL>alter database recover managed standby database disconnect from session;
#执行此命令后,备库会切换到自动恢复模式。
如果要启动到实时日志应用模式 (注:前提必须创建standby logfile)
#切换备库到适时应用日志模式,即real-time apply
alter database recover managed standby database using current logfile disconnect from session; #执行这个命令后,会切断这个session,执行的功能与上面相同。
SQL>alter database recover managed standby database using current logfile disconnect from session;
注意:以上模式数据库还没有打开,不能查询数据库中的表
切换standby database到read only模式
SQL> alter database recover managed standby database cancel; #首先取消备库的自动恢复模式
SQL>alter database open read only;
SQL>shutdown immediate #需要关闭后才会进行切换
如果要切换回recover manage模式(启动日志应用或者启动日志实时应用)
SQL>startup nomount
SQL>alter database mount standby database; #执行此命令后备库会处于手动恢复状态。
SQL> alter database recover managed standby database disconnect from session; 启动日志应用
SQL>alter database recover managed standby database using current logfile disconnect from session; 启动日志实时应用
4、启动和关闭顺序
启动顺序
(1).启从、主库的监听Listener
从库DG-Standby:
$lsnrctl start
主库DG-Primary:
$lsnrctl start
(2).启动备库数据库,执行如下:
$sqlplus /nolog
SQL>conn /as sysdba
SQL> startup nomount
SQL> alter database mount standby database; #让备库处于standby
SQL> alter database recover managed standby database using current logfile disconnect from session; #开始实时同步
(3).启动主库
$sqlplus /nolog
SQL>conn /as sysdba
SQL> startup
关闭顺序
关闭的时候正好相反,先关闭主库,然后关闭从库。
(1). 关闭主库
$su �C oracle
SQL>sqlplus /nolog
SQL>conn /as sysdba
SQL>shutdown immediate;
(2). 关闭从库
su �C oracle
SQL>sqlplus /nolog
SQL>conn /as sysdba
SQL>alter database recover managed standby database cancel; #停止同步
SQL>shutdown immediate
5、功能切换
Switchover状态切换
首先在primary上操作:
(1). 验证主库是否能执行角色转换到备库(原主库执行)
SQL> SELECT SWITCHOVER_STATUS FROM V$DATABASE;
SWITCHOVER_STATUS
TO STANDBY 1 row selected
(2).开始把物理主库改变为物理备库(原主库执行)
SQL> ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY;
或
SQL> ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY with session shutdown;
注:如果有活动的session可以使用此选项,否则转换会遇到ORA-01093错误,也可以杀掉活动会话或等活动会话后进行转换
(3).关闭并重启主库(原主库执行)
SQL> shutdown immediate
SQL> startup nomount
SQL> alter database mount standby database; #让备库处于standby
SQL> alter database recover managed standby database using current logfile disconnect from session; #开始实时同步
然后在standby上操作:
(1).验证备库是否能执行角色转换到主库(原备库执行)
SQL> SELECT SWITCHOVER_STATUS FROM V$DATABASE;
SWITCHOVER_STATUS
TO_PRIMARY
1 row selected
(2).开始把物理备库转换成物理主库(原备库执行)
SQL> ALTER DATABASE COMMIT TO SWITCHOVER TO PRIMARY;
--如果报ORA-16139: media recovery required,可能是由于未应用日志引起,可先执行
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;
(3)打开备库,然后关闭重启.(原备库执行)
SQL> SHUTDOWN IMMEDIATE;
SQL> STARTUP;
(4) 验证是否转换成功(原备库执行)
SQL> ALTER SYSTEM SWITCH LOGFILE;
启动日志应用
(5) 应用归档日志(原主库上执行),不需要执行
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT FROM SESSION;
小窍门:要想顺利的实现switchover,最好在每台server上都同时设置好primary和standby的一些初始化参数,虽然其中一些参数只有在primary或者standby其中之一上起作用。
应急切换
(注:模拟主库由于故障无法正常switchover,需要执行failover,强制备库->pridb并接管业务)
(1).在备库上操作:
由于是failover,所以理解主库这时候已经无法正常使用,只需备库切换至primary db
停止应用恢复模式
alter database recover managed standby database finish;
转换standby db为primary db
alter database commit to switchover to primary;
重启数据库,恢复正常业务
SQL>shutdown immediate
SQL>startup
select open_mode,database_role from v$database;
OPEN_MODE DATABASE_ROLE
OPEN PRIMARY
注:failover将破坏dataguard模式,需要重新配置dataguard
Failover状态切换
在备库上进行切换:
1.首先停止备库的自动恢复状态:
SQL>alter database recover managed standby database finish;
如果没有使用过standby redo log的话执行:
SQL>alter database recover managed standby database finish skip standby logfile;
2.切换备库到主库:
SQL>alter database commit to switchover to primary;
关闭数据库:
SQL>shutdown immediate;
启动数据库:
SQL>startup;
Active状态切换:
Active是从8i延续过来的,其实不建议采用:
在备库上执行切换:
1:alter database recover managed standby database cancel;
2:alter database activate standby database;
3:shutdown immediate
总结一下Failover 和 Switchover 的区别:
在9i 的dataguad环境中:
1:执行Switch Over 必须是Primary 正常,并且是必须Primary 主动先Switch成 standby.然后standby 才能switch 成primary。
2:如果需要作成primary出问题,standby 能接管的话,必须作 failover ,而不是SwitchOver。
Failover :
将主数据库offline,备用数据库online,这种操作由系统和软件失败引起。 即使在备用数据库上应用重做日志,也可能出现数据丢失的现象,除非备用数据库运行在 guaranteed protection 模式。
原主数据库重新使用时必须重新启动实例。
其它的备用数据库也需重新启动实例。
Switchover :
故意将主数据库offline,而将另一备用数据库online,它能够切换到备用数据库而不需同步操作。如:可使用 Switchover 完成系统的平滑升级。 即使在备用数据库上不应用重做日志,也不会造成数据的丢失。
数据库不需重新启动实例。这使主数据库几乎能立即在备用数据库上恢复它的功能,因此可经常进行定期维护而不需中断操作。
Failover和Switchover的区别为:
当Failover发生,备用数据库切换为主数据库之后,它丢失了备用数据库的所有能力,也就是说,不能再返回到备用模式;而Switchover可以,备用数据库可切换为主数据库,也可从主数据库再切换回备用数据库。
四、相关视图
v$archive_dest
v$archive_dest_status
v$log_history
v$archvied_log
v$managed_standby
v$archive_gap
6、常见问题
(1). 日志无法传送
SQL>select dest_name,status,error from v$archive_dest;
察看相应的归档路径的状态是否 valid ,否则根据error 信息进行处理
(2). 无法使用alter database 重命名 data file
在standby 上,当设置 standby_file_management 为auto 时,不允许下列操作
alter database rename
alter database add/drop logfile
alter database add/drop standby logfile member
alter database create datafile as
(3). switchover 失败
SQL>alter database commit to switchover to physical standby
错误: ORA-01093:alter database close only permitted with no session connected
可以察看引起该错误的活动 session
SQL> select sid,process,program from v$session where type='USER' and
sid<>(select distinct sid from v$mystat);
然后根据查出的 sid 结合v$session 视图最后用
alter system kill session ‘ sid,serial’ 来kill 掉进程,断开该 session
或者使用如下命令来做 switchover
SQL>alter database commit to switchover to physical standby with session shutdown;
(4). 在standby database 的 read only模式下做 report 时出现错误:
ora-01220:file base sort illegal before database is open.
可能原因: standby database 没有temporary tablespace
(5).当主机和备机在运行过程中,把备机停下来,主机的归档日志将不能传到备机,当把备机服务起来后,主机的归档日志也不能传到备机,需要把主机的所有服务都重启一次才可以传日志。
请问为什么需要把主机要重启一次呢?有没有不需要重启主机就可以解决此问题呢?
发生这种情况时,核查几处:
( 1) . show parameter log_archive_dest ;
( 2) . select REOPEN_SECS,MAX_FAILURE from V$ARCHIVE_DEST;
察看是否是因为由于备机没有开机,造成 primary node 无法正常传送 archived log,并且达到了最大允许的失败次数。如果是这样,可以通过 alter system set log_archive_dest... 来重置属性值,恢复日志的正常传送。
也可以手工传送相关的日志到备机,
对于物理standby : ALTER DATABASE REGISTER LOGFILE '/xxx/xxx/arcr_xxx.arc'
对于逻辑standby : ALTER DATABASE REGISTER LOGICAL LOGFILE '/xxx/xxx/arcr_xxx.arc'
(3). 执行SELECT MESSAGE FROM V$DATAGUARD_STATUS; 察看相关信息,还有根据 dataguard 的不同类型来察看相关的 view 来确定当前的状态,具体参见 dataguard 的官方文档。




