 MySQL如何创建高性能索引
MySQL如何创建高性能索引1.独立的列不能使用索引:
MYSQL>select actor_id from sakila.actor whereactor_id+1=5;
MYSQL>select ... where to_days(current_date) -to_days(data_col)<=10;
2.前缀索引和索引选择性:
前缀索引:对于很长的VARCHAR列和BLOB,TEXT列使用,因为索引不能存放在很长的字符
索引选择性:是指不重复的索引值(cardinality)和数据表的记录总数的比值
索引选择性=不重复的索引值/数据表的记录总数 取值范围: 0-1之间
索引选择性越高,查询性能越高,选择性高可以让MYSQL在技术要求肌肤过滤掉更多的行
查询对于VARCHAR列,不同前缀长度的选择性:
root@db5.7.18[sakila]> select count(distinctleft(city,12))/count(*) as sel12,
-> count(distinctleft(city,13))/count(*) as sel13,
-> count(distinctleft(city,14))/count(*) as sel14,
-> count(distinctleft(city,15))/count(*) as sel15 from city_demo;
+--------+--------+--------+--------+
| sel12 | sel13 | sel14 | sel15 |
+--------+--------+--------+--------+
| 0.0711 | 0.0712 | 0.0713 | 0.0713 |
+--------+--------+--------+--------+
1 row in set (0.05 sec)
当前缀取值为前14个字符时,索引选择性最好
创建前缀索引:
alter table sakila.city_demo add indexidx_city(city(14));
缺点:
前缀索引无法使用ORDERBY和GROUP BY ,也无法使用覆盖索引扫描
多列索引:
索引列的顺序意味前着索引首先按照最左列进行排序,其次是第二列....
经验法则:将选择性最高的列放到索引的最前列,
查看where条件列对应返回的数据量:
root@db5.7.18[sakila]> select* from city where country_id=103 and last_update='2006-02-1504:45:25';
root@db5.7.18[sakila]> selectsum(country_id=103),sum(last_update='2006-02-15 04:45:25')from city;
+---------------------+----------------------------------------+
| sum(country_id=103) |sum(last_update='2006-02-15 04:45:25') |
+---------------------+----------------------------------------+
| 35 | 600 |
+---------------------+----------------------------------------+
1 row in set (0.00 sec)
root@db5.7.18[sakila]> select count(*) from citywhere last_update='2006-02-15 04:45:25';
+----------+
| count(*) |
+----------+
| 600 |
+----------+
1 row in set (0.00 sec)
root@db5.7.18[sakila]> select count(*) from city wherecountry_id=103;
+----------+
| count(*) |
+----------+
| 35 |
+----------+
1 row in set (0.00 sec)
以上显示说明SQL语句(select * from city where country_id=103 andlast_update='2006-02-15 04:45:25'; )
country_id只会返回35条数据,last_update='2006-02-1504:45:25'返回600条数据
查看多列的选择性:
root@db5.7.18[sakila]> select count(distinctcountry_id)/count(*) as country_id_selectivity, count(distinctlast_update)/count(*) as last_update_selectivity, count(*) fromcity;
+------------------------+-------------------------+----------+
| country_id_selectivity | last_update_selectivity |count(*) |
+------------------------+-------------------------+----------+
| 0.1817 | 0.0017 | 600 |
+------------------------+-------------------------+----------+
1 row in set (0.00 sec)
总结:如果要对country_id和last_update创建多列索引,就将country_id放在第一列,将last_update放在第二列
sql>alter table city add indexidx_country_update(country_id,last_update)
聚簇索引
聚簇索引不是一种单独的索引类型,而是一种数据存储方式
当表有聚簇索引时,它的数据行实际上存放在索引的叶子页(left page)中,聚簇,表示数据行和相邻的键值紧凑地存储在一起,所有一个表只能有一个聚簇索引
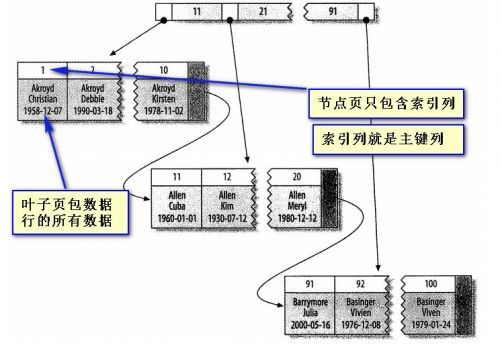
INNODB只聚集在同一个页面的记录,包含相邻键值的页面可能会相距很远
特点:
可以把相关数据保存在一起
将索引和数据保存在同一个B-TREE中
使用覆盖索引可以直接使用页节点中的主键值
缺点:
如果数据全部入在内存中,访问顺序就没有那么重要,聚簇索引就没有的优势
插入速度严重依赖插入顺序,如果是随机插入,数据插入完成后需要用OPTIMIZE TABLE TABLE_NAME 优化一下表
更新成本很高,更新需要重新排序
全表扫描更慢
二级索引(非聚集)的叶子节点包含了引用行的主键列
二级索引访问需要两次IO查询,不是一次,因为二级索引叶子节点保存的不是指向行的物理位置的指针,而是行的主键值,这意为着通过二级索引查找行时,存储引擎需要找到二级索引的叶子节点获取对应的主键值,然后根据这个值去聚簇索引中查找到对应的行,所以做了两次B-TREE查找,而不是一次
INNODB和MyISAM索引和保存数据的区别:
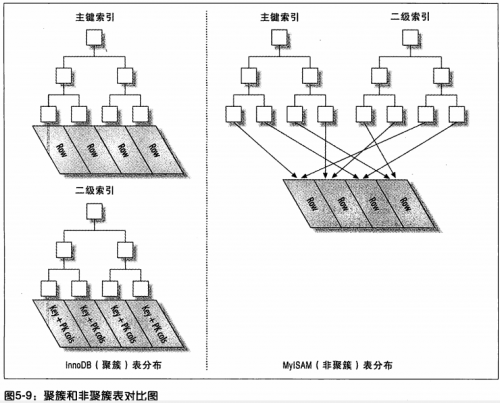
在Innodb表中按主键顺序插入行:
1.创建表时定义主键AUTO_INCREMENT自增属性
2.不要使用UUID来做为聚簇索引的主键
建议:使用INNODB时应该尽可能地按主键顺序插入数据,并且尽可能地使用单调增加的聚簇键的值来插入新行
覆盖索引:
如果一个索引包含所有需要查询的字段值,就不需要再回表再查行数据了,这种索引就叫覆盖索引
覆盖索引必须存储索引列的值,哈希索引,空间索引,全文索引都不存储索引列的值
如果一条SQL使用覆盖索引,在使用EXPLAIN时会显示:using index
eg:
explain select store_id,film_id from sakila.inventory
key:idx_store_id_file_id
Extra:using index
以上SQL使用了覆盖索引
eg:
explain select * from products whereactor='sean carrey'
key:actor
Extra:using where #表示在存储引擎层返回WHRE条件的数据,在数据库层进行了过滤
以上SQL没有使用覆盖索引,因为查询从表中选择了所有列,而没有任何索引覆盖了所有的列
使用覆盖索引来优化SQL:
创建三个数据列的覆盖索引:(artist,title,prod_id)
select * from products join (select prod_id fromproducts where actor='SEAN CARREY' and title like'%apollo%') as t1 on (t1.prod_id=products.prod_id)
注意:对于两个以上组合索引时,SQL查询的字段如果是范围查询,则这个字段后面的索引将不可以,只能做前缀匹配索引,优化方法是:尽可能将需要做范围查询的列放到索引的后面,以便优化器能使用尽可能多的索引列
使用索引扫描来做排序:
有两种方式可以生成有序的结果:
1.通过排序的操作
2.按索引顺序扫描
如果EXPLAIN的TYPE为INDEX,表示MYSQL使用了索引扫描来做排序
按索引顺序读取数据的速度通常要比顺序地全表扫描慢
使用索引来对结果做排序的条件:
只有当索引的列顺序和ORDERBY 子句的顺序完全一致,并且所有列的排序方向都一样时
如果查询需要关联多张表,则只有当ORDER BY 子句引用的字段全部为第一个表时
对于组合索引(两个以上字段),索引需要满足最左前缀匹配的要求
压缩(前缀压缩)索引:
会影响性能,不建议使用
冗余和重复索引:
MYSQL允许在相同列上创建多个索引,优化器在优化查询时需要逐个进行考虑,会影响性能
重复索引是指在相同的列上按照相同的顺序创建的相同类型的索引
同一个字段创建类型不同的索引不是重复的索引
冗余索引:
如果创建了索引(A,B),又创建了索引(A),则(A)就是冗余索引 ,但如果再创建索引(B,A),(B,A)就不是冗余索引
如果再创建(B),因为(B)不是(A,B)的左前缀,所以也不是(A,B)的冗余索引
如果先有索引(A),再修改索引将主键索引也加入,变成(A,ID),其中这个ID也是冗余的,因为创建索引(A)时,已包含了主键,创建索引(A)时,相关于创建了索引(A,ID)
这种索引对以下SQL非常有用:
select * from employees where A=5 order by id
但如果创建组合索引,(A,B),相当于创建了索引(A,B,ID),如果再使用以下SQL.将无法使用索引
select * from employees where A=5 order by id
扩展索引,让索引能覆盖查询:(state_id,city,address)组合索引
以下SQL将用到覆盖索引:
SQL>select state_id,city,address from userinfo wherestate_id=5;
索引会影响到数据的插入速度,单张表索引越多,会导致DML操作变慢
未使用的索引:
未使用的索引应该删除
如何查找未使用的索引:
1.在Percona或mariadb中,打开userstates服务器变量,运行一段时间后,通过查看INFORMATION_SCHEMA.INDEX_STATISTICS来查看索引的使用频率:
2.使用perconaToolkis中的pt-index_usage工具来查看
索引和锁:
索引可以让查询锁定更少的行,INNODB只有在访问行的时候才会对其加锁,而索引能够减少INNODB访问的行数,从而减少锁的数据
如果索引无法过滤掉无效的行,那么在INNODB检索到数据并返回给MYSQL服务层以后,MYSQL服务器才能应用WHERE子句
root@db5.7.18[sakila]> explain select actor_id fromsakila.actor where actor_id<5 and actor_id<>1 \G;
*************************** 1. row***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: NULL
rows: 4
filtered: 100.00
Extra: Using where; Usingindex
1 row in set, 1 warning (0.00 sec)
分析:底层存储引擎的操作是:从索引的开头开始获取满足条件actor_id<5的记录,服务器并没有告诉INNODB可以过滤第1行的WHERE条件,Extra中出现Using where,这个表示mysql服务器将存储引擎返回行以后再应用where 过滤条件
SQL中使用IN的问题:
WHERE eye_colorIN('BROWN','BLUE','HAZEL')AND hair_colorIN('BLACK','RED','BLONDE','BROWN')and sex in ('M',"F")
优化器则会转化成4*3*2=24种组合,执行计划需要检查where子句中的所有的24种组合,这会导致很多问题,使SQL分析变慢
优化排序:
低选择性列优化:
对于选择性非常低的列,可以增加一些特殊的索引来做排序:
可以创建(sex,rating来优化下面的查询)
mysql>select <cols> from profiles wheresex='M' order by rating limit 10;
分页优化:
select <cols> from profiles wheresex='M' order by rating limit 100000,10; 如果分页越后面,查询会越慢
优化方法:
1.在业务层面控制分页数量
2.延迟关联,通过使用覆盖索引查询返回需要的主键,再根据这些主键关联原表获得需要的行,这可以减少MYSQL扫描那些需要丢掉的行数
select <cols> from profiles inner join (select<primary key cols> from profiles where x.sex='M' orderby rating limit 100000,10) as x using(<primary key cols>);
维护索引和表:
目的:找到并修复损坏的表,维护准确的索引统计信息,减少碎片
1.通过check tabletable_name来检查表是否发生了损坏,索引是否发生了损坏
2.可以通过altertable innodb_tab1 engine=innodb;
3.将数据表先导出,再导入
数据损坏恢复工具:
直接从INNODB数据文件恢复出数据:
工具:mysql-innodb-data-recovery-tools
更新索引统计信息:
如果存储引擎向优化器提供的扫描行数信息是不准备的数据,或者执行计划本身太复杂以致无法准确地获取各个阶段匹配的行数,那么优级器会使用索引统计信息来估算扫描的行数,如果统计信息不准确,优化器就很可能做出错误的执行计划
INNODB引擎通过抽样的方式来计算统计信息,首先随机地读取少量的索引页面,然后以此为样本计算索引的统计信息,在旧版本中样本页码是8个数据页,新版本可以通过参数:innodb_stats_sample_pages来配置样本的数据
show variables like '%innodb_stats_sample_pages%';
手动收集统计信息:
通过运行ANALYZETABLE TABLE_NAME来重新生成统计信息
数据库自动收集统计信息:
在表首次打开,或执行ANALYZETABLE 或表大小发生非常大的变化时(变化超过1/16或新插入了20亿行会触发)自动计算统计信息,在打开INFORMATION_SCHEMA或SHOW TABLE STATUS 或SHOW INDEX时会自动收集统计信息
innodb_stats_on_metadata可以控制运行以上命令是否会自动更新统计信息,默认为OFF,表示运行以上命令,不会自动收集表的统计信息
查看表中所有索引的基数:
show index from sakila.actor
Key_name: idx_actor_last_name
Seq_in_index: 1
Column_name: last_name
Collation: A
Cardinality: 121 #表示存储引擎估算索引列有多少个不同的取值
减少索引和数据的碎片:
数据存储的碎片化有以下三种类型:
行碎片(rowfragmenttation)
数据行被存储为多个地方的多个片段中
行间碎片(intra-rowfragmenttation)
逻辑上顺序的页,行在磁盘上不是顺序存储的,对全表扫描有影响
剩余空间碎片(Freespace fragmenttation)
数据页码中有大量的空余空间,会导致读取大量不需要的数据
解决方法:
可以通过执行OPTIMIZETABLE TABLE_NAME 或导出导入的方式来重新整理数据,对于索引,可以通过先删除,再创建索引的方式来消除碎片
也可以通过alter tabletable_name engine=innodb来执行
如果排除表是否有碎片:
通过Percona的 XtraBackup 的--stats参数以非备份的方式运行,打开索引和表的统计情况,可以确定数据的碎片化程序




