 用一次你就会爱上它,MySQL在线DDL工具gh-ost
用一次你就会爱上它,MySQL在线DDL工具gh-ost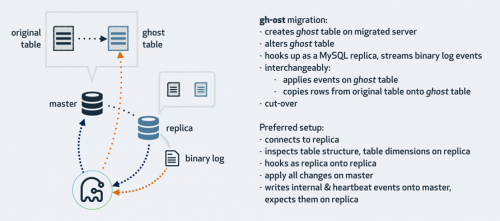
生产环境中我们都会遇到在线修改MySQL表结构的事,如果是小表(10W-100W)左右的数据量,还比较好处理,如果是订单或日志类的在线表,就会比较麻烦,在没有这个工具以前,只能等到数据库访问底峰或凌晨来处理。还好有gh-ost这个工具,简直是DBA的福星,下面就详细介绍以下这款神器。
简介:
gh-ost基于 golang 语言,是 github 开源的一个 DDL 工具,是 GitHub's Online Schema Transmogrifier/Transfigurator/Transformer/Thingy 的缩写,意思是 GitHub 的在线表定义转换器。
gh-ost 放弃了触发器,使用 binlog 来同步。gh-ost作为一个伪装的备库,可以从主库/备库上拉取 binlog,过滤之后重新应用到主库上去,相当于主库上的增量操作通过 binlog 又应用回主库本身,不过是应用在幽灵表上。
gh-ost 首先连接到主库上,根据 alter 语句创建幽灵表,然后作为一个”备库“连接到其中一个真正的备库上,一边在主库上拷贝已有的数据到幽灵表,一边从备库上拉取增量数据的 binlog,然后不断的把 binlog 应用回主库。图中 cut-over 是最后一步,锁住主库的源表,等待 binlog 应用完毕,然后替换 gh-ost 表为源表。gh-ost 在执行中,会在原本的 binlog event 里面增加以下 hint 和心跳包,用来控制整个流程的进度,检测状态等。这种架构带来诸多好处,例如:
整个流程异步执行,对于源表的增量数据操作没有额外的开销,高峰期变更业务对性能影响小。
降低写压力,触发器操作都在一个事务内,gh-ost 应用 binlog 是另外一个连接在做。
可停止,binlog 有位点记录,如果变更过程发现主库性能受影响,可以立刻停止拉binlog,停止应用 binlog,稳定之后继续应用。
可测试,gh-ost 提供了测试功能,可以连接到一个备库上直接做 Online DDL,在备库上观察变更结果是否正确,再对主库操作,心里更有底
它有三种架构模式:
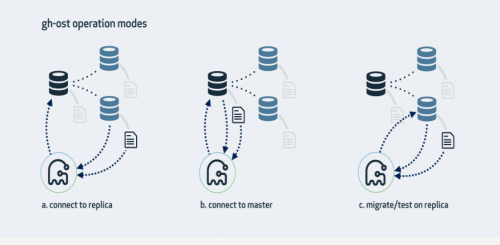
1、连上从库,在主库上修改
这是gh-ost默认的工作模式,它会查看从库情况,找到集群的主库并且连接上去,对主库侵入最少,大体步骤是:
在主库上创建_xxx_gho、_xxx_ghc,并修改_xxx_gho表结构;
从slave上读取二进制日志事件,将变更应用到主库上的_xxx_gho表;
在主库上读源表的数据写入_xxx_gho表中:insert into igore....select;
在主库上完成表切换;
2、直接主库修改
在主库上创建_xxx_gho、_xxx_ghc,并修改_xxx_gho表结构;
从主库上读取二进制日志事件,将变更应用到主库上的_xxx_gho表;
在主库上读源表的数据写入_xxx_gho表中:insert into igore....select;
在主库上完成表切换;
3、在从库上修改和测试
这种模式会在从库上做修改。gh-ost仍然会连上主库,但所有操作都是在从库上做的,不会对主库产生任何影响。在操作过程中,gh-ost也会不时地暂停,以便从库的数据可以保持最新。
--migrate-on-replica选项让gh-ost直接在从库上修改表。最终的切换过程也是在从库正常复制的状态下完成的。
--test-on-replica表明操作只是为了测试目的。在进行最终的切换操作之前,复制会被停止。原始表和临时表会相互切换,再切换回来,最终相当于原始表没被动过。主从复制暂停的状态下,你可以检查和对比这两张表中的数据。
安装配置:
非常简单,几条命令就可以搞定:
在github上下载:
wget https://github.com/github/gh-ost/releases/download/v1.1.1/gh-ost-1.1.1-1.x86_64.rpm
rpm -ivh gh-ost-1.1.1-1.x86_64.rpm
生产环境配置案例:
数据库环境:
[root@node240 ~]# uname -a
Linux node240 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
[root@node240 ~]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
[root@node240 ~]# mysql -V
mysql Ver 8.0.20 for Linux on x86_64 (MySQL Community Server - GPL)
使用说明:条件是操作的MySQL上需要的binlog模式是ROW。如果在一个从上测试也必须是ROW模式,还要开启log_slave_updates。根据上面的参数说明按照需求进行调整。
1. 在主库上运行:单实例上DDL: 单个实例相当于主库,需要开启--allow-on-master参数和数据库日志的ROW模式。
[root@node240 ~]#
gh-ost --user="root" --password="Rsc123456." --host=localhost --database="test" --table="tt" --initially-drop-old-table --alter="ADD COLUMN dd6 varchar(10),add column dd5 int not null default 0 comment 'test' " --execute --assume-rbr --allow-on-master --initially-drop-old-table --initially-drop-ghost-table --ok-to-drop-table
2. 在主库上运行:主从上DDL:
有2个选择,一是按照1直接在主上执行同步到从上,另一个连接到从库,在主库做迁移(只要保证从库的binlog为ROW即可,主库不需要保证):
[root@node240 ~]# gh-ost --user="root" --password="Rsc123456." --host=localhost --database="test" --table="tt" --initially-drop-old-table --alter="ADD COLUMN y8 varchar(10),add column y9 int not null default 0 comment 'test' " --allow-on-master --execute --allow-on-master --initially-drop-old-table --initially-drop-ghost-table --ok-to-drop-table
此时的操作大致是:
行数据在主库上读写
读取从库的二进制日志,将变更应用到主库
在从库收集表格式,字段&索引,行数等信息
在从库上读取内部的变更事件(如心跳事件)
在主库切换表
在执行DDL中,从库会执行一次stop/start slave,要是确定从的binlog是ROW的话可以添加参数:--assume-rbr。如果从库的binlog不是ROW,可以用参数--switch-to-rbr来转换成ROW,此时需要注意的是执行完毕之后,binlog模式不会被转换成原来的值。--assume-rbr和--switch-to-rbr参数不能一起使用。
3. 在从库上运行:在从上进行DDL测试:(从库要开启binlog日志)
[root@node241 mysql]# gh-ost --user="root" --password="Rsc123456." --host=127.0.0.1 --database="test" --table="tt" --alter="ADD COLUMN abcd1 varchar(10),add column abcd2 int not null default 0 comment 'test' " --test-on-replica --switch-to-rbr --execute --test-on-replica-skip-replica-stop --initially-drop-ghost-table
测试完成后可以对比一下原表与gho表不同的表结构:
原表:
mysql> desc tt;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int | NO | PRI | NULL | |
| cc2 | varchar(10) | YES | | NULL | |
| cc3 | int | NO | | 0 | |
| ccc3 | varchar(10) | YES | | NULL | |
| ccc4 | int | NO | | 0 | |
| dd3 | varchar(10) | YES | | NULL | |
| dd4 | int | NO | | 0 | |
| dd6 | varchar(10) | YES | | NULL | |
| dd5 | int | NO | | 0 | |
| y1 | varchar(10) | YES | | NULL | |
| y2 | int | NO | | 0 | |
| y4 | varchar(10) | YES | | NULL | |
| y3 | int | NO | | 0 | |
| y8 | varchar(10) | YES | | NULL | |
| y9 | int | NO | | 0 | |
+-------+-------------+------+-----+---------+-------+
15 rows in set (0.01 sec)
修改字段后的表:
mysql> desc _tt_gho;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int | NO | PRI | NULL | |
| cc2 | varchar(10) | YES | | NULL | |
| cc3 | int | NO | | 0 | |
| ccc3 | varchar(10) | YES | | NULL | |
| ccc4 | int | NO | | 0 | |
| dd3 | varchar(10) | YES | | NULL | |
| dd4 | int | NO | | 0 | |
| dd6 | varchar(10) | YES | | NULL | |
| dd5 | int | NO | | 0 | |
| y1 | varchar(10) | YES | | NULL | |
| y2 | int | NO | | 0 | |
| y4 | varchar(10) | YES | | NULL | |
| y3 | int | NO | | 0 | |
| y8 | varchar(10) | YES | | NULL | |
| y9 | int | NO | | 0 | |
| abcd1 | varchar(10) | YES | | NULL | |
| abcd2 | int | NO | | 0 | |
+-------+-------------+------+-----+---------+-------+
17 rows in set (0.00 sec)
参数--test-on-replica:在从库上测试gh-ost,包括在从库上数据迁移(migration),数据迁移完成后stop slave,原表和ghost表立刻交换而后立刻交换回来。继续保持stop slave,使你可以对比两张表。如果不想stop slave,则可以再添加参数:--test-on-replica-skip-replica-stop
上面三种是gh-ost操作模式,上面的操作中,到最后不会清理临时表,需要手动清理,再下次执行之前果然临时表还存在,则会执行失败,可以通过参数进行删除:
--initially-drop-ghost-table:gh-ost操作之前,检查并删除已经存在的ghost表。该参数不建议使用,请手动处理原来存在的ghost表。默认不启用该参数,gh-ost直接退出操作。
--initially-drop-old-table:gh-ost操作之前,检查并删除已经存在的旧表。该参数不建议使用,请手动处理原来存在的ghost表。默认不启用该参数,gh-ost直接退出操作。
--initially-drop-socket-file:gh-ost强制删除已经存在的socket文件。该参数不建议使用,可能会删除一个正在运行的gh-ost程序,导致DDL失败。
--ok-to-drop-table:gh-ost操作结束后,删除旧表,默认状态是不删除旧表,会存在_tablename_del表。
4)额外说明:终止、暂停、限速
gh-ost --user="root" --password="root" --host=192.168.163.131 --database="test" --table="t1" --alter="ADD COLUMN o2 varchar(10),add column o1 int not null default 0 comment 'test' " --exact-rowcount --serve-socket-file=/tmp/gh-ost.t1.sock --panic-flag-file=/tmp/gh-ost.panic.t1.flag --postpone-cut-over-flag-file=/tmp/ghost.postpone.t1.flag --allow-on-master --execute
① 标示文件终止运行:--panic-flag-file
创建文件终止运行,例子中创建/tmp/gh-ost.panic.t1.flag文件,终止正在运行的gh-ost,临时文件清理需要手动进行。
② 表示文件禁止cut-over进行,即禁止表名切换,数据复制正常进行。--postpone-cut-over-flag-file
创建文件延迟cut-over进行,即推迟切换操作。例子中创建/tmp/ghost.postpone.t1.flag文件,gh-ost 会完成行复制,但并不会切换表,它会持续的将原表的数据更新操作同步到临时表中。
③ 使用socket监听请求,操作者可以在命令运行后更改相应的参数。--serve-socket-file,--serve-tcp-port(默认关闭)
创建socket文件进行监听,通过接口进行参数调整,当执行操作的过程中发现负载、延迟上升了,不得不终止操作,重新配置参数,如 chunk-size,然后重新执行操作命令,可以通过scoket接口进行动态调整。如:
暂停操作:
#暂停
echo throttle | socat - /tmp/gh-ost.test.t1.sock
#恢复
echo no-throttle | socat - /tmp/gh-ost.test.t1.sock
修改限速参数:
echo chunk-size=100 | socat - /tmp/gh-ost.t1.sock
echo max-lag-millis=200 | socat - /tmp/gh-ost.t1.sock
echo max-load=Thread_running=3 | socat - /tmp/gh-ost.t1.sock
对比:
跟gh-ost差不多功能的就是pt工具中的pt-online-schema-change,两种工具各有优缺点,现对比如下:
1. 表没有写入并且参数为默认的情况下,二者DDL操作时间差不多,毕竟都是copy row操作。
2. 表有大量写入(sysbench)的情况下,因为pt-osc是多线程处理的,很快就能执行完成,而gh-ost是模拟“从”单线程应用的,极端的情况下,DDL操作非常困难的执行完毕。
结论:虽然gh-ost不需要触发器,对于主库的压力和性能影响也小很多,但是针对高并发的场景进行DDL效率还是比pt-osc低,所以还是需要在业务低峰的时候处理。相关的测试可以看gh-ost和pt-osc性能对比。




