 MySQL数据实时同步至StarRocks集群配置详解
MySQL数据实时同步至StarRocks集群配置详解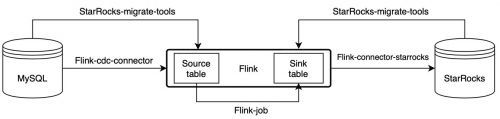
功能简介
StarRocks 提供 Flink CDC connector、flink-connector-starrocks 和 StarRocks-migrate-tools(简称smt),实现 MySQL 数据实时同步至 StarRocks,满足业务实时场景的数据分析。
基本原理
通过 Flink CDC connector、flink-connector-starrocks 和 smt 可以实现 MySQL 数据的秒级同步至StarRocks。 MySQL 同步
如图所示,Smt 可以根据 MySQL 和 StarRocks 的集群信息和表结构自动生成 source table 和 sink table 的建表语句。
通过 Flink-cdc-connector 消费 MySQL 的 binlog,然后通过 Flink-connector-starrocks 写入 StarRocks。
场景五:通过CDC+SMT实现MySQL多表数据的秒级同步
场景四是针对单表的数据同步,那种方式只能同步数据,并不能同步表结构,我们需要先在目标库中创建对应的表,然后再执行同步任务同步数据。但若需要同步的数据表比较多或者需要整库同步,在StarRocks中逐个建表就会比较麻烦,在Flink中逐个写任务也会相对繁琐。
为了友好的解决多表同步时的问题,StarRocks发布了StarRocks-migrate-tools(简称smt)工具,来快捷生成StarRocks表结构和Flink-SQL映射表及同步语句。Smt目前可用于MySQL、PostgreSQL、Oracle和hive,后面三个数据库的同步还在公测中,我们就先以MySQL来进行演示,后续Release版发布后再逐个补充。
StarRocks-migrate-tools下载地址:
https://cdn-thirdparty.starrocks.com/smt.tar.gz
操作步骤
修改/etc/my.cnf,开启 MySQL binlog
#开启 binlog 日志
log-bin =/var/lib/mysql/mysql-bin
#log_bin = ON
##binlog 日志的基本文件名
#log_bin_basename =/var/lib/mysql/mysql-bin
##binlog 文件的索引文件,管理所有 binlog 文件
#log_bin_index =/var/lib/mysql/mysql-bin.index
#配置 serverid
server-id = 1
binlog_format = row
重启mysqld,然后可以通过 SHOW VARIABLES LIKE 'log_bin'; 确认是否已经打开。
下载 Flink, 推荐使用 1.13,最低支持版本 1.11。
下载 Flink CDC connector,请注意下载对应 Flink 版本的 Flink-MySQL-CDC。
下载 Flink-connector-starrocks,请注意 1.13 版本和 1.11/1.12 版本使用不同的 connector.
https://github.com/StarRocks/starrocks-connector-for-apache-flink/releases/download/v1.2.5/flink-connector-starrocks-1.2.5_flink-1.13_2.12.jar
复制 flink-sql-connector-mysql-cdc-xxx.jar, flink-connector-starrocks-xxx.jar 到 flink-xxx/lib/
下载并解压 smt.tar.gz
wget https://cdn-thirdparty.starrocks.com/smt.tar.gz
将文件复制到flink-1.13.2目录下
[root@node181 conf]# pwd
/usr/local/flink-1.13.2/conf
[root@node181 conf]# ls
config_prod.conf log4j-cli.properties log4j.properties logback-console.xml logback.xml workers
flink-conf.yaml log4j-console.properties log4j-session.properties logback-session.xml masters zoo.cfg
[root@node181 flink-1.13.2]# pwd
/usr/local/flink-1.13.2
[root@node181 flink-1.13.2]# ls
bin conf examples lib LICENSE licenses log NOTICE opt plugins README.txt starrocks-migrate-tool
[root@node181 flink-1.13.2]# chmod 755 starrocks-migrate-tool
解压并修改配置文件 :
Db 需要修改成 MySQL 的连接信息。
be_num 需要配置成 StarRocks 集群的节点数(这个能帮助更合理的设置 bucket 数量)。
[table-rule.1] 是匹配规则,可以根据正则表达式匹配数据库和表名生成建表的 SQL,也可以配置多个规则。
flink.starrocks.* 是 StarRocks 的集群配置信息,参考 [Flink-connector-starrocks 配置]。
[db]
host = 192.168.1.1
port = 3306
user = root
password =
[other]
# number of backends in StarRocks
be_num = 3
# `decimal_v3` is supported since StarRocks-1.18.1
use_decimal_v3 = false
# file to save the converted DDL SQL
output_dir = ./result
[table-rule.1]
# pattern to match databases for setting properties
database = ^console_19321.*$
# pattern to match tables for setting properties
table = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://192.168.1.1:9030
flink.starrocks.load-url= 192.168.1.1:8030
flink.starrocks.username=root
flink.starrocks.password=
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=15000
执行 starrocks-migrate-tool,flink 和 starrocks 建表语句都生成在 result 目录下
$./starrocks-migrate-tool
$ls result
flink-create.1.sql smt.tar.gz starrocks-create.all.sql
flink-create.all.sql starrocks-create.1.sql
利用上一步生成的 StarRocks 的建表语句在 StarRocks 中建表
Mysql -hxx.xx.xx.x -P9030 -uroot -p < starrocks-create.1.sql
执行如下语句,生成Flink table 并开始同步,同步任务会持续执行
需要确保flink集群已经启动,未启动可以使用flink/bin/start-cluster.sh启动
bin/sql-client.sh -f flink-create.1.sql
这个执行以后同步任务会持续执行
如果是 Flink 1.13 之前的版本可能无法直接执行脚本,需要逐行提交
观察任务状况
bin/flink list
[root@node181 bin]#bin/flink list
Waiting for response...
------------------ Running/Restarting Jobs -------------------
14.02.2023 09:39:06 : 532f68714cad5ac5b291ed8ce33dee98 : insert-into_default_catalog.nsy_product.report_google_analytics_sink (RUNNING)
14.02.2023 09:39:09 : 92286881db8c1df2409ebd7a45983e2d : insert-into_default_catalog.nsy_product.report_google_analytics_2019_sink (RUNNING)
14.02.2023 09:39:13 : 697afd936a6ea238b5640925487898f0 : insert-into_default_catalog.nsy_product.report_google_analytics_2020_sink (RUNNING)
14.02.2023 09:39:16 : 459f395f46a41304777e658e62460cae : insert-into_default_catalog.nsy_product.report_google_analytics_2021_sink (RUNNING)
14.02.2023 09:39:20 : 7dfe3de6516ca0b59e8cbb978cf4374a : insert-into_default_catalog.nsy_product.report_google_analytics_product_daily_sink (RUNNING)
14.02.2023 09:39:23 : 020281e97371ab214189608b43f5b539 : insert-into_default_catalog.nsy_product.report_google_analytics_product_summary_sink (RUNNING)
--------------------------------------------------------------
上述命令可以查看 flink 同步任务状态,如果有任务请查看 log 日志,或者调整 conf/flink-conf.yaml 中的系统配置中内存和 slot,具体配置请参考 Flink 配置参数。
注意事项:
如果有多组规则,需要给每一组规则匹配 database,table 和 flink-connector 的配置
[table-rule.1]
# pattern to match databases for setting properties
database = ^console_19321.*$
# pattern to match tables for setting properties
table = ^.*$
flink sink configurations
DO NOT set connector, table-name, database-name, they are auto-generated
flink.starrocks.jdbc-url=jdbc:mysql://192.168.1.1:9030
flink.starrocks.load-url= 192.168.1.1:8030
flink.starrocks.username=root
flink.starrocks.password=
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=15000
[table-rule.2]
pattern to match databases for setting properties
database = ^database2.*$
pattern to match tables for setting properties
table = ^.*$
flink sink configurations
DO NOT set connector, table-name, database-name, they are auto-generated
flink.starrocks.jdbc-url=jdbc:mysql://192.168.1.1:9030
flink.starrocks.load-url= 192.168.1.1:8030
flink.starrocks.username=root
flink.starrocks.password=
如果导入数据不方便选出合适的分隔符可以考虑使用 Json 格式,但是会有一定的性能损失, 使用方法:用以下参数替换 flink.starrocks.sink.properties.column_separator 和 flink.starrocks.sink.properties.row_delimiter 参数
flink.starrocks.sink.properties.strip_outer_array=true
flink.starrocks.sink.properties.format=json
#参数说明),比如可以给不同的规则配置不同的导入频率等参数。
* 针对分库分表的大表可以单独配置一个规则,比如:有两个数据库 edu_db_1,edu_db_2,每个数据库下面分别有course_1,course_2 两张表,并且所有表的数据结构都是相同的,通过如下配置把他们导入StarRocks的一张表中进行分析。
[table-rule.3]
pattern to match databases for setting properties
database = ^edu_db_[0-9]*$
pattern to match tables for setting properties
table = ^course_[0-9]*$
flink sink configurations
DO NOT set connector, table-name, database-name, they are auto-generated
flink.starrocks.jdbc-url = jdbc: mysql://192.168.1.1:9030
flink.starrocks.load-url = 192.168.1.1:8030
flink.starrocks.username = root
flink.starrocks.password =
flink.starrocks.sink.properties.column_separator =\x01
flink.starrocks.sink.properties.row_delimiter =\x02
flink.starrocks.sink.buffer-flush.interval-ms = 5000
这样会自动生成一个多对一的导入关系,在StarRocks默认生成的表名是 course__auto_shard,也可以自行在生成的配置文件中修改。
* 如果在sql-client中命令行执行建表和同步任务,需要做对'\'字符进行转义
'sink.properties.column_separator' = '\\x01'
'sink.properties.row_delimiter' = '\\x02'




