 十年双11:阿里数据库变迁“三部曲”
十年双11:阿里数据库变迁“三部曲”2018 年,双 11 迎来了十周年。十年间,依赖于迅速崛起的互联网技术以及各项新兴技术的沉淀,阿里巴巴缔造了全球数字经济时代的第一“操作系统”。

在这个操作系统上,让全球消费者和商家买、卖、逛、听、看、游得顺心、放心、舒心。
十年间,阿里巴巴的技术同学和全球开发者们,一起把互联网前沿技术转化为全球消费者、全球数字经济参与者可以感知的便利。
如今,它已不仅仅是全球消费者的狂欢节,更是名副其实的全球互联网技术的演练场。
从“双 11 的技术”到“技术的双 11”,每一次化“不可能”为“可能”的过程,都是阿里人对技术的不懈追求。
在第十个双 11 来临之际,有幸邀请到参与多年双 11 备战的核心技术大牛――双11技术保障部大队长、数据库事业部研究员张瑞,通过这篇万字长文,带领大家回顾双 11 这十年来数据库领域的技术变迁。
十年使命:推动中国数据库技术变革
再过几天,我们即将迎来第十个双 11。过去十年,阿里巴巴技术体系的角色发生了转变,从双 11 推动技术的发展,变成了技术创造新商业。
很多技术通过云计算开始对外输出,变成了普惠的技术,服务于各个行业,真正做到了推动社会生产力的发展。
这十年,阿里巴巴数据库团队一直有一个使命:推动中国数据库技术变革。从商业数据库到开源数据库再到自研数据库,我们一直在为这个使命而努力奋斗。
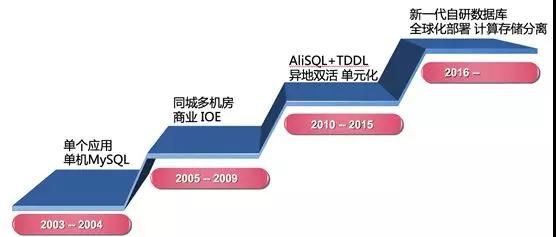
如果将阿里数据库发展历史分为三个阶段的话,分别是:
- 2005 年-2009 年:商业数据库时代。
- 2010 年-2015 年:开源数据库时代。
- 2016 年-至今:自研数据库时代。
商业数据库时代就是大家所熟知的 IOE 时代,后来发生了一件大事就是“去 IOE”。
通过分布式数据库中间件 TDDL、开源数据库 AliSQL(阿里巴巴的 MySQL 分支)、高性能 X86 服务器和 SSD,并通过 DBA 和业务开发同学的共同努力,成功地替换了商业数据库 Oracle、IBM 小型机和 EMC 高端存储,从此进入了开源数据库时代。

去 IOE 带来了三个重大的意义:
- 解决了扩展性的问题,让数据库具备了横向扩展(弹性)的能力,为未来很多年双11零点交易峰值打下了很好的基础。
- 自主可控,我们在 AliSQL 中加入了大量的特性,比如:库存热点补丁,SQL 限流保护,线程池等等,很多特性都是来源于双 11 对于数据库的技术要求,这在商业数据库时代是完全不可能的。
- 稳定性,原来在商业数据库时代,就如同把所有的鸡蛋放在一个篮子里(小型机),去 IOE 之后不仅仅解决了单机故障,更是通过异地多活的架构升级让数据库跨出了城市的限制,可以实现数据库城市间的多活和容灾,大大提升了系统的可用性。
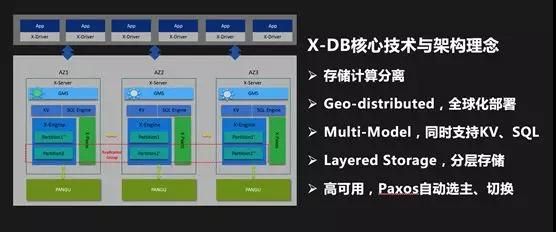
进入 2016 年,我们开始自研数据库,代号 X-DB。大家一定会问:为什么要自研数据库?有以下几个原因:
- 我们需要一个能够全球部署的原生分布式数据库,类似于 Google Spanner。
- 双 11 的场景对数据库提出了极高的要求:在双 11 零点需要数据库提供非常高的读写能力。
数据库使用 SSD 来存储数据,而数据存在明显的冷热特性,大量冷的历史数据和热的在线数据存放在一起,日积月累,占用了大量宝贵的存储空间,存储成本的压力越来越大。
- 我们经过认真评估后发现,如果继续在开源数据库基础上进行改进已经无法满足业务需求。
- 新的硬件技术的出现,如果说 SSD 的大规模使用和 X86 服务器性能的极大提升推动了去 IOE 的进程,那么NVM非易失内存,FPGA 异构计算,RDMA 高速网络等技术将第二次推动数据库技术的变革。
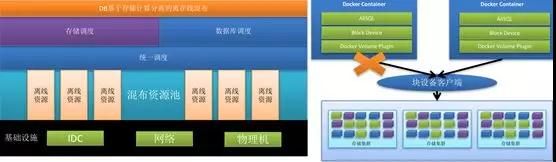
伴随着每一年的双 11 备战工作,机器资源的准备都是非常重要的一个环节。如何降低双 11 的机器资源成本一直是阿里技术人不断挑战自我的一个难题。
第一个解决方案就是使用云资源,数据库从 2016 年初开始就尝试使用高性能 ECS 来解决双 11 的机器资源问题。
通过这几年的双 11 的不断磨练,2018 年双 11,我们可以直接使用公有云 ECS,并通过 VPC 网络与阿里巴巴集团内部环境组成混合云,实现了双 11 的弹性大促。
第二个方案就是在线离线混部,日常让离线任务跑在在线(应用和数据库)的服务器上,双 11 大促在线应用使用离线的计算资源,要实现这种弹性能力,数据库最核心要解决一个技术问题就是:存储计算分离。
存储计算分离后,数据库可以在双 11 使用离线的计算资源,从而实现极致的弹性能力。通过使用云资源和混部技术,可以最大程度降低双 11 交易峰值带来的成本。
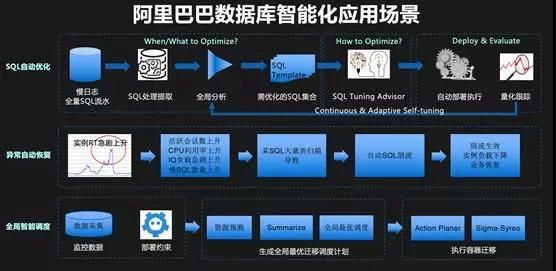
双 11 备战中另外一个重要的技术趋势就是:智能化。数据库和智能化相结合也是我们一直在探索的一个方向,比如 Self-driving Database 等。
2017 年,我们第一次使用智能化的技术对 SQL 进行自动优化,2018 年,我们计划全网推广 SQL 自动优化和空间自动优化,希望可以使用这些技术降低 DBA 的工作负担,提升开发人员效率,并有效提升稳定性。
相信未来,在双 11 的备战工作中,会有越来越多的工作可以交给机器来完成。
我从 2012 年开始参加双 11 的备战工作,多次作为数据库的队长和技术保障部总队长,在这么多年的备战工作中,我也经历了很多有意思的故事,在这里分享一些给大家。
2012 年:我的第一次双 11
2012 年是我的第一次双 11,在此之前,我在 B2B 的数据库团队,2012 年初,整个集团的基础设施团队都合并到了技术保障部,由振飞带领。
我之前从来没有参加过双 11,第一年参加双 11 后羿(数据库团队的负责人)就把队长的职责给了我,压力可想而知。
那时候备战双 11 的工作非常长,大概从 5、6 月份就开始准备了,最重要的工作就是识别风险,并准确评估出每个数据库的压力。
我们需要把入口的流量转换为每个业务系统的压力 QPS,然后我们根据业务系统的 QPS 转换为数据库的 QPS。
2012 年还没有全链路压测的技术,只能靠每个业务系统的线下测试,以及每个专业线队长一次又一次的开会 Review 来发现潜在的风险。
可想而知,这里面存在巨大的不确定性,每个人都不想自己负责的业务成为短板,而机器资源往往是有限的,这时,就完全靠队长的经验了,所以,每个队长所承担的压力都非常巨大。
我记得当年双 11 的大队长是李津,据说他当时的压力大到无法入睡,只能在晚上开车去龙井山顶,打开车窗才能小憩一会。
而我,由于是第一年参加双 11,经验为零,完全处于焦虑到死的状态,幸好当年有一群很靠谱的兄弟和我在一起。
他们刚刚经历了去 IOE 的洗礼,并且长期与业务开发浸淫在一起,对业务架构和数据库性能如数家珍,了若指掌。
通过他们的帮助,我基本摸清了交易整套系统的架构,这对我未来的工作帮助非常大。
经过几个月紧张的准备,双 11 那天终于到来了,我们做好了最充分的准备,但是一切都是那么地不确定。
我们怀着忐忑不安的心情,当零点到来的时候,最坏的情况还是发生了:库存数据库的压力完全超过了容量,同时 IC(商品)数据库的网卡也被打满了。
我记得很清楚,当时我们看着数据库上的监控指标,束手无策。这里有一个小细节:由于我们根本没有估算到这么大的压力,当时监控屏幕上数据库的压力指标显示超过了 100%。
正在这时,技术总指挥李津大喊一声:“大家都别慌!”这时我们才抬头看到交易的数字不断冲上新高,心里才稍微平静下来。
事实上,对于 IC 数据库网卡被打满,库存数据库超过容量,都超出了我们的预期,所以最终我们什么预案也没做,就这样度过了零点的高峰。
因为这些原因,2012 年的的双 11 产生了大量的超卖,给公司带来了很大的损失。
那一年的双 11 后,库存、商品、退款和相应数据库的同学,为了处理超卖导致的问题,没日没夜加了两周的班。
而且,我周围很多朋友,都在抱怨高峰时的用户体验实在太糟糕了。我们下决心要在第二年的双 11 解决这些问题。
2013 年:库存热点优化和不起眼的影子表
2012 年的双 11 结束后,我们就开始着手解决库存数据库的性能提升。
库存扣减场景是一个典型的热点问题,即多个用户去争抢扣减同一个商品的库存(对数据库来说,一个商品的库存就是数据库内的一行记录),数据库内对同一行的更新由行锁来控制并发。
我们发现当单线程(排队)去更新一行记录时,性能非常高,但是当非常多的线程去并发更新一行记录时,整个数据库的性能会跌到惨不忍睹,趋近于零。
当时数据库内核团队做了两个不同的技术实现:一个是排队方案,另一个是并发控制方案。
两者各有优劣,解决的思路都是要把无序的争抢变为有序的排队,从而提升热点库存扣减的性能问题。
两个技术方案通过不断的完善和 PK,最终都做到了成熟稳定,满足业务的性能要求,最终为了万无一失,我们把两个方案都集成到了 AliSQL(阿里巴巴的 MySQL 分支)中,并且可以通过开关控制。
最终,我们通过一整年的努力,在 2013 年的双 11 解决了库存热点的问题,这是第一次库存的性能提升。
在这之后的 2016 年双 11,我们又做了一次重大的优化,把库存扣减性能在 2013 年的基础上又提升了十倍,称为第二次库存性能优化。
2013 年堪称双 11 历史上里程碑式的一年,因为这一年出现了一个突破性的技术-全链路压测。
我非常佩服第一次提出全链路压测理念的人-李津,他当时问我们:有没有可能在线上环境进行全仿真的测试?
所有人的回答都是:不可能!当然,我认为这对于数据库是更加不可能的,最大的担心是压测流量产生的数据该如何处理,从来没听说过哪家公司敢在线上系统做压测,万一数据出现问题,这个后果将会非常严重。
我记得在 2013 年某天一个炎热的下午,我正在库存数据库的问题中焦头烂额的时候,叔同(全链路压测技术负责人)来找我商量全链路压测数据库的技术方案。
就在那个下午,我们两个人讨论出了一个“影子表”的方案,即在线上系统中建立一套“影子表”来存储和处理所有的压测数据,并且由系统保证两套表结构的同步。
但是,我们对这件事心里都没底,我相信在双 11 的前几周,没有几个人相信全链路压测能够落地,我们大部分的准备工作还是按照人工 Review+线下压测的方式进行。
但是,经过所有人的努力,这件事竟然在双 11 前两周取得了突破性进展,当第一次全链路压测成功的时候,所有人都觉得不敢相信。
最后,双 11 的前几个晚上,几乎每天晚上都会做一轮全链路压测,每个人都乐此不疲,给我留下的印象实在太深刻了。
但这个过程,也并不是一帆风顺,我们压出了很多次故障,多次写错了数据,甚至影响了第二天的报表,长时间高压力的压测甚至影响了机器和 SSD 的寿命。
即便出现了如此多的问题,大家依然坚定地往前走,我觉得这就是阿里巴巴与众不同的地方,因为我们相信所以看见。
事实也证明,全链路压测变成了双 11 备战中最有效的大杀器。
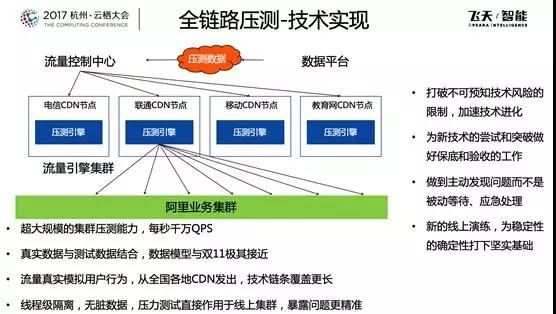
如今,全链路压测技术已经成为阿里云上的一个产品,变成了更加普惠的技术服务更多企业。
2015 年:大屏背后的故事
2015 年,我从数据库的队长成为整个技术保障部的总队长,负责整个技术设施领域的双 11 备战工作,包括 IDC、网络、硬件、数据库、CDN,应用等所有技术领域。
我第一次面对如此多的专业技术领域,对我又是一次全新的挑战。但是,这一次我却被一个新问题难倒了:大屏。
2015 年,我们第一次举办天猫双 11 晚会,这一年晚会和媒体中心第一次不在杭州园区,而是选择在北京水立方,媒体中心全球 26 小时直播。
全球都在关注我们双 11 当天的盛况,需要北京杭州两地协同作战,困难和挑战可想而知!
大家都知道对媒体直播大屏来说最最重要的两个时刻,一个是双 11 零点开始的时刻,一个是双 11 二十四点结束的时刻,全程要求媒体直播大屏上跳动的 GMV 数字尽可能的不延迟。
那一年我们为了提升北京水立方现场的体验及和杭州总指挥中心的互动,在零点前有一个倒计时环节,连线杭州光明顶作战指挥室,逍遥子会为大家揭幕 2015 双 11 启动,然后直接切换到我们的媒体大屏,所以对 GMV 数字的要求基本上是零延迟,这个挑战有多大不言而喻!
然而,第一次全链路压测时却非常不尽人意,延时在几十秒以上,当时的总指挥振飞坚决的说:GMV 第一个数字跳动必须要在 5 秒内。
既要求 5 秒内就拿到实时的交易数字,又要求这个数字必须是准确的,所有人都觉得这是不可能完成的任务。
当时,导演组也提了另外一个预案,可以在双 11 零点后,先显示一个数字跳动的特效(不是真实的数字)。
等我们准备好之后,再切换到真实的交易数字,但对媒体大屏来说所有屏上的数据都必须是真实且正确的(这是阿里人的价值观)。
所以我们不可能用这个兜底的方案,所有人想的都是如何把延迟做到 5 秒内,当天晚上,所有相关的团队就成立一个大屏技术攻关组,开始封闭技术攻关。
别看一个小小的数字,背后涉及应用和数据库日志的实时计算、存储和展示等全链路所有环节,是真正的跨团队技术攻关。


最终不负众望,我们双 11 零点 GMV 第一个数字跳动是在 3 秒,严格控制在 5 秒内,是非常非常不容易的!
不仅如此,为了保证整个大屏展示万无一失,我们做了双链路冗余,类似于飞机双发动机,两条链路同时计算,并可实时切换。
我想大家一定不了解大屏上一个小小的数字,背后还有如此多的故事和技术挑战吧。双 11 就是如此,由无数小的环节组成,背后凝聚了每个阿里人的付出。
2016 年:吃自己的狗粮
做过大规模系统的人都知道,监控系统就如同我们的眼睛一样,如果没有它,系统发生什么状况我们都不知道。
我们数据库也有一套监控系统,通过部署在主机上的 Agent,定期采集主机和数据库的关键指标,包括:CPU 和 IO 利用率,数据库 QPS、TPS 和响应时间,慢 SQL 日志等等。
并把这些指标存储在数据库中,进行分析和展示,最初这个数据库也是 MySQL。
随着阿里巴巴数据库规模越来越大,整个监控系统就成为了瓶颈,比如:采集精度,受限于系统能力,最初我们只能做到 1 分钟,后来经过历年的优化,我们把采集精度提升到 10 秒。
但是,最让人感到尴尬的是:每一年双 11 零点前,我们通常都有一个预案,对监控系统进行降级操作,比如降低采集精度,关闭某些监控项等等。这是因为高峰期的压力太大,不得已而为之。
另外一个业务挑战来自安全部,他们对我们提出一个要求,希望能够采集到每一条在数据库上运行的 SQL,并能实时送到大数据计算平台进行分析。
这个要求对我们更是不可能完成的任务,因为每一个时刻运行的 SQL 是非常巨大的,通常的做法只能做到采样,现在要求是一条不漏的记录下来,并且能够进行分析,挑战非常大。
2016 年双 11,我们启动了一个项目:对我们整个监控系统进行了重新设计。
目标:具备秒级监控能力和全量 SQL 的采集计算能力,且双 11 峰值不降级。
第一是要解决海量监控数据的存储和计算问题,我们选择了阿里巴巴自研的时序数据库 TSDB,它是专门针对 IOT 和 APM 等场景下的海量时序数据而设计的数据库。
第二是要解决全量 SQL 的采集和计算的问题,我们在 AliSQL 内置了一个实时 SQL 采集接口,SQL 执行后不需要写日志就直接通过消息队列传输到流计算平台上进行实时处理,实现了全量 SQL 的分析与处理。
解决了这两个技术难题后,2016 年双 11,我们达到了秒级监控和全量 SQL 采集的业务目标。
后来,这些监控数据和全量 SQL 成为了一个巨大的待挖掘的宝库,通过对这些数据的分析,并与 AI 技术相结合,我们推出了 CloudDBA 数据库智能化诊断引擎。
我们相信数据库的未来是 Self-driving Database,它有四个特性:自诊断、自优化、自决策和自恢复。如前文所述,目前我们在智能化方向上已经取得了一些进展。
现在,TSDB 已经是阿里云上的一个产品,而 CloudDBA 除了服务阿里巴巴内部数万工程师,也已经在云上为用户提供数据库优化服务。
我们不仅吃自己的狗粮,解决自己的问题,同时也用阿里巴巴的场景不断磨练技术,服务更多的云上用户。这就是双 11 对技术的推动作用。
2016-2017:数据库和缓存那点儿事
在双 11 的历史上,阿里巴巴自研缓存-Tair 是非常重要的技术产品,数据库正是因为有了 Tair 的帮助,才扛起了双 11 如此巨大的数据访问量。
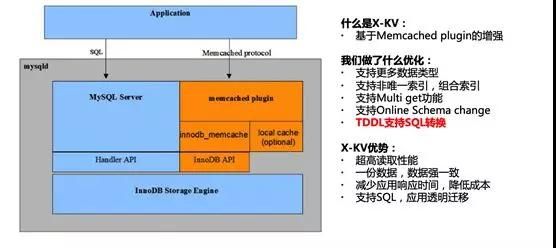
在大规模使用 Tair 的同时,开发同学也希望数据库可以提供高性能的 KV 接口,并且通过 KV 和 SQL 两个接口查询的数据是一致的,这样可以大大简化业务开发的工作量,X-KV 因此因用而生。
它是 X-DB 的 KV 组件,通过绕过 SQL 解析的过程,直接访问内存中的数据,可以实现非常高的性能以及比 SQL 接口低数倍的响应时间。
X-KV 技术在 2016 年双 11 第一次得到了应用,用户反馈非常好,QPS 可以做到数十万级别。
在 2017 年双 11,我们又做了一个黑科技,通过中间件 TDDL 自动来实现 SQL 和 KV 的转换。
开发不再需要同时开发两套接口,只需要用 SQL 访问数据库,TDDL 会自动在后台把 SQL 转换为 KV 接口,进一步提升了开发的效率,降低了数据库的负载。
2016 年双 11,Tair 碰到了一个业界技术难题:热点。大家都知道缓存系统中一个 Key 永远只能分布在一台机器上。
但是双 11 时,热点非常集中,加上访问量非常大,很容易就超出了单机的容量限制,CPU 和网卡都会成为瓶颈。
由于热点无法预测,可能是流量热点,也可能是频率热点,造成 2016 年双 11 我们就像消防队员一样四处灭火,疲于奔命。
2017 年,Tair 团队的同学就在思考如何解决这个业界的技术难题,并且创新性地提出了一种自适应热点的技术方案:
- 智能识别技术, Tair 内部采用多级 LRU 的数据结构,通过将访问数据 Key 的频率和大小设定不同权值,从而放到不同层级的 LRU 上。
这样淘汰时可以确保权值高的那批 Key 得到保留,最终保留下来且超过阈值设定的就会判断为热点 Key。
- 动态散列技术,当发现热点后,应用服务器和 Tair 服务端就会联动起来,根据预先设定好的访问模型,将热点数据动态散列到 Tair 服务端其他数据节点的 Hot Zone 存储区域去访问。
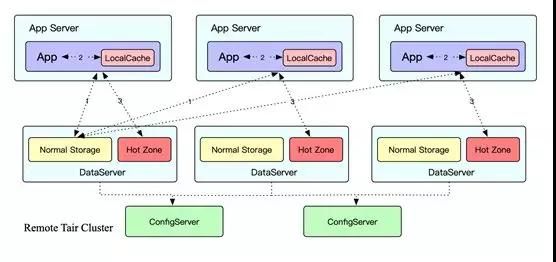
热点散列技术在 2017 年双 11 中取得了非常显著的效果,通过将热点散列到整个集群,所有集群的水位均降低到了安全线下。
如果没有这个能力,那么 2017 年双 11 很多 Tair 集群都可能出现问题。
可以看出,数据库和缓存是一对互相依赖的好伙伴,他们互相借鉴,取长补短,共同撑起了双11海量数据存储和访问的一片天。
2016-2017 年:如丝般顺滑的交易曲线是如何做到的
自从有了全链路压测这项技术后,我们希望每一年双 11 零点的交易曲线都能如丝般顺滑,但是事情往往不像预期的那样顺利。
2016 年双 11 零点后,交易曲线出现了一些波动,才逐步攀升到最高点。
事后复盘时,我们发现主要的问题是购物车等数据库在零点的一刹那,由于 Buffer pool 中的数据是“冷”的。
当大量请求在零点一瞬间到来时,数据库需要先“热”起来,需要把数据从 SSD 读取到 Buffer pool 中,这就导致瞬间大量请求的响应时间变长,影响了用户的体验。
知道了问题原因后,2017 年我们提出了“预热”技术,即在双 11 前,让各个系统充分“热”起来,包括 Tair,数据库,应用等等。
为此专门研发了一套预热系统,预热分为数据预热和应用预热两大部分,数据预热包括:数据库和缓存预热,预热系统会模拟应用的访问,通过这种访问将数据加载到缓存和数据库中,保证缓存和数据库 BP 的命中率。
应用预热包括:预建连接和 JIT 预热,我们会在双 11 零点前预先建立好数据库连接,防止在高峰时建立连接的开销。
同时,因为业务非常复杂,而 Java 代码是解释执行的,如果在高峰时同时做 JIT 编译,会消耗大量的 CPU,系统响应时间会拉长,通过 JIT 预热,保证代码可以提前充分编译。
2017 年双 11,因为系统有了充分的预热,交易曲线在零点时划出了一道完美的曲线。
2017-2018 年:存储计算分离的技术突破
2017 年初,集团高年级技术同学们发起了一个技术讨论:到底要不要做存储计算分离?由此引发了一场扩日持久的大讨论。
包括我在王博士的班上课时,针对这个问题也进行了一次技术辩论,由于两方观点势均力敌,最终谁也没有说服谁。
对于数据库来说,存储计算分离更加是一个非常敏感的技术话题,大家都知道在 IOE 时代,小型机和存储之间通过 SAN 网络连接,本质上就是属于存储计算分离架构。
现在我们又要回到这个架构上,是不是技术的倒退?另外,对于数据库来说,IO 的响应延时直接影响了数据库的性能,如何解决网络延时的问题?各种各样的问题一直困扰着我们,没有任何结论。
当时,数据库已经可以使用云 ECS 资源来进行大促弹性扩容,并且已经实现了容器化部署。
但是,我们无论如何也无法回避的一个问题就是:如果计算和存储绑定在一起,就无法实现极致的弹性,因为计算节点的迁移必须“搬迁”数据。
而且,我们研究了计算和存储的能力的增长曲线,我们发现在双 11 高峰时,对于计算能力的要求陡增。
但是对于存储能力的要求并没有发生显著变化,如果可以实现存储计算分离,双 11 高峰我们只需要扩容计算节点就可以了。
综上所述,存储计算分离是华山一条路,必须搞定。
2017 年中,为了验证可行性,我们选择在开源分布式存储 Ceph 的基础上进行优化,与此同时,阿里巴巴自研高性能分布式存储盘古 2.0 也在紧锣密鼓的开发中。
另外一方面,数据库内核团队也参与其中,通过数据库内核优化减少网络延迟对数据库性能的影响。
经过大家的共同努力,最终基于盘古 2.0 的计算存储分离方案都在 2017 年双 11 落地,并且验证了使用离线机头挂载共享存储的弹性方案。经过这次双 11,我们证明了数据库存储计算分离是完全可行的。
存储计算分离的成功离不开一位幕后英雄:高性能和低延迟网络,2017 年双 11 我们使用了 25G 的 TCP 网络。
为了进一步降低延迟,2018 年双 11 我们大规模使用了 RDMA 技术,大幅度降低了网络延迟,这么大规模的 RDMA 应用在整个业界都是独一无二的。
为了降低 IO 延迟,我们在文件系统这个环节也做了一个大杀器-DBFS,通过用户态技术,旁路 Kernel,实现 I/O 路径的 Zero copy。
通过这些技术的应用,达到了接近于本地存储的延时和吞吐。
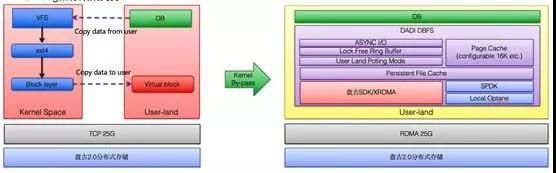
2018 年双 11,随着存储计算分离技术的大规模使用,标志着数据库进入了一个新的时代。
总结
在 2012 年到 2018 年的这六年,我见证了零点交易数字的一次次提升,见证了背后数据库技术的一次次突破,更见证了阿里人那种永不言败的精神,每一次化“不可能”为“可能”的过程都是阿里技术人对技术的不懈追求。
感恩十年双 11,期待下一个十年更美好。




