 RHCE:通过grep使用正则表达式
RHCE:通过grep使用正则表达式RHCE:通过grep使用正则表达式:
查找文本文件的内容的行(只能匹配数据的行):
grep语法:
grep [options] parrern filename
[root@foundation0 grep]# cat grep.txt
abc
bcd
test
grepa
ba
b2
-c 只输出匹配行的计数
[root@foundation0 grep]# grep -c a grep.txt
3
-i 不区分大小写 忽略大小写
[root@foundation0 grep]# grep -i "^a.*y$" grep.txt
Ay
Ammmy
Ammy
-h 查询多文件时不显示文件名
[root@foundation0 ~]# grep -h root /etc/passwd /etc/group
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
root:x:0:
-s 如果没有匹配到则不显示,错误信息不显示
[root@foundation0 grep]# grep -s a grep.txt
abc
grepa
ba
[root@foundation0 grep]# grep -s efg grep.txt
[root@foundation0 grep]# echo $?
1
[root@foundation0 grep]# grep -s efg grep #输入了错误的文件名,通过使用-s 就不会报错
[root@foundation0 grep]#
-w 精确匹配
[root@foundation0 grep]# ip a | grep -w inet #只匹配有一个单词的这一行,是因为匹配了这个单词,所有匹配了这一行
inet 127.0.0.1/8 scope host lo
-v 取反,匹配与正则表达式相反的行
[root@foundation0 grep]# cat grep.txt
abc
bcd
test
grepa
ba
b2
[root@foundation0 grep]# grep -v^b grep.txt
abc
test
grepa
[root@foundation0 grep]# grep [0-9] grep.txt
b2#因为匹配了数字2,所以显示了这一行
089
123
3456
2b
[root@foundation0 grep]# grep -v [0-9] grep.txt #匹配不是数字的行
abc
bcd
test
grepa
ba
AxyzxyzxyzxyzxyzC
Zmmmmmmmmmmy
Ay
Ammmy
xyz
abc
Ammy
bd
-Anum 显示匹配行的下num行
[root@node230 grep]# grep -A1 "^a" grep.txt
abc
bcd
[root@node230 grep]# grep -A2 "^a" grep.txt
abc
bcd
Test
-Bnum 显示匹配行的上num行
[root@foundation0 grep]# grep -B1 test grep.txt
bcd
test
-Anum -Bnum 显示匹配行的上num行和下num行
[root@foundation0 grep]# grep -A1 -B1 test grep.txt
bcd
test
grepa
-C num [-Cnum] 显示匹配行的上num行和下num行
[root@node230 grep]# grep -C 1 "^g" grep.txt
test
grepa
ba
[root@node230 grep]# grep -C 2 "^g" grep.txt
bcd
test
grepa
ba
b2
^pattern 匹配以pattern开头的行
[root@foundation0 grep]# grep "^b" grep.txt
bcd
ba
b2
pattern$ 匹配以pattern结尾的行
[root@foundation0 grep]# grep "d$" grep.txt
bcd
. 匹配任意单个字符
[root@foundation0 grep]# grep "." grep.txt
abc
bcd
test
grepa
ba
b2
* :匹配任意长度的单个字符,.代表任意单个字符,*表示重复前面字符的0次或多次,*号前面一定要有字符或数字,*号前的可以是字符,也可以是字符组成的组(.*),*只对它前面的一个字符或组起作用,再前面的字符不受影响
[root@foundation0 grep]# grep ".*" grep.txt
abc
bcd
test
grepa
ba
b2
[pattern] 匹配指定范围内的任一一个字符
[root@foundation0 grep]# grep [Ay] grep.txt #匹配A 或者y 或者Ay
Ay
Ammmy
Ammy
[root@foundation0 grep]# grep [0-9x-zX-z] grep.txt #包含开头和结尾的字符
b2
AxyzxyzxyzxyzxyzC
Zmmmmmmmmmmy
Ay
Ammmy
089
xyz
Ammy
[^pattern]:指定匹配范围外的字符,也就是不匹配显示的字符,’非’的意思
[root@foundation0 grep]# grep [^1-3] grep.txt #不包含数字123
abc
bcd
test
grepa
ba
b2
AxyzxyzxyzxyzxyzC
Zmmmmmmmmmmy
Ay
Ammmy
089
xyz
abc
Ammy
^[pattern]以pattern开头的行:
[root@foundation0 grep]# grep ^[0-9] grep.txt
089
POSIX格式:
[[:alpha:]] 匹配字母字符
[[:lower:]] 匹配小写字母字符
[[:upper:]] 匹配大写字母字符
[[:digit:]] 匹配数字
[[:alnum:]] 匹配字母数字字符
[[:space:]] 匹配空白字符(禁止打印),如回车符、换行符、竖直制表符和换页符
[[:punct:]] 匹配标点字符
[[:cntrl:]] 匹配控制字符(禁止打印)
[[:print:]] 匹配可打印字符
? 表示匹配前面字符0次或1次\?
[root@foundation0 grep]# grep "b\?d" grep.txt
bcd
Bd
[root@foundation0 grep]# echo "za" | grep "z\(a\?\)"
Za
[root@foundation0 grep]# grep "Am\?y" grep.txt #基础正则表达式,要加转意字符\
Ay
[root@foundation0 grep]# grep "Am?y" grep.txt
[root@foundation0 grep]# grep -E "Am?y" grep.txt #扩展正则表达式,相当于egrep "Am?y" grep.txt
Ay
[root@foundation0 grep]# grep "A\(m\)\?y" grep.txt #只重复前面括号内的字符0次或1次
Ay
""匹配所有任意字符
[root@foundation0 grep]# grep "" grep.txt
abc
bcd
test
grepa
ba
{m,n}匹配前面的字符串从m到n次的行
[root@foundation0 grep]# grep "Zm\{3,10\}y" grep.txt
Zmmmmmmmmmmy
[root@foundation0 grep]# grep -E "Zm{3,10}y" grep.txt
Zmmmmmmmmmmy
[root@foundation0 grep]# grep -E 'Zm{3,10}y' grep.txt
Zmmmmmmmmmmy
{n,}匹配前面的字符串至少n次的行,包含n次,相关于>=n次
[root@node230 grep]# grep -E "Zm{3,}y" grep.txt
Zmmmmmmmmmmmmmmmmy
{,n}匹配前面的字符串至多n次的行,包含n次,相关于<=n次
[root@node230 grep]# grep -E "Am{,3}y" grep.txt
Ay
Ammmy
Ammy
[root@node230 grep]# grep -E "Am{,2}y" grep.txt
Ay
Ammy
()分组匹配几次前面组的行,括号内指定的组重复的次数
[root@foundation0 grep]# grep -E "A(xyz){5}C" grep.txt
AxyzxyzxyzxyzxyzC
[root@foundation0 grep]# grep -E "A(xyz){5,5}C" grep.txt
AxyzxyzxyzxyzxyzC
[root@foundation0 grep]# grep -E "A(xyz){1,}C" grep.txt
AxyzxyzxyzxyzxyzC
以\<pattern为开头,以\>结尾的行
[root@foundation0 grep]# grep -E "\<A.*C\>" grep.txt
AxyzxyzxyzxyzxyzC
[root@foundation0 grep]# grep -E "^A.*C$" grep.txt
AxyzxyzxyzxyzxyzC
[root@foundation0 grep]# grep "^[a-z]a$" grep.txt
ba
+ 表示匹配前面的字符串一次或多次
[root@foundation0 grep]# echo "redhat" | grep -E "(re)(d+)"
redhat
[root@foundation0 grep]# grep -E "A(xyz)+C" grep.txt
AxyzxyzxyzxyzxyzC
| 表示或关系 \|
[root@foundation0 grep]# grep -E "vmx|svm" /proc/cpuinfo
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts
mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts nopl xtopology
tsc_reliable nonstop_tsc aperfmperf pni pclmulqdq vmx ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe
popcnt aes xsave avx f16c rdrand hypervisor lahf_lm 3dnowprefetch ida arat pln pts dtherm tpr_shadow
vnmi ept vpid fsgsbase smep
对以上配置的总结:
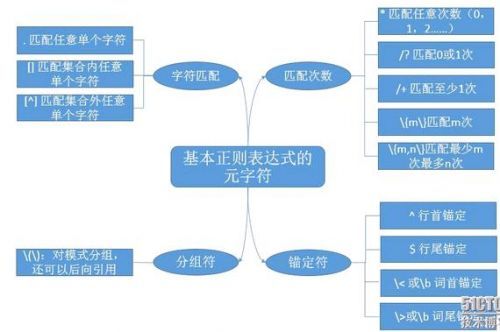
一.匹配字符
. 匹配任意单个字符
[ ] 匹配指定范围内的任意字符
[^] 匹配飞指定范围内的任意字符
[:alpha:] 字母字符
[:lower:] 小写字母字符
[:upper:] 大写字母字符
[:digit:] 数字
[:alnum:] 字母数字字符
[:space:] 空白字符(禁止打印),如回车符、换行符、竖直制表符和换页符
[:punct:] 标点字符
[:cntrl:] 控制字符(禁止打印)
[:print:] 可打印字符
使用时一般使用两个中括号,具体会在下面的例子中使用。
二.匹配次数
* 匹配前面的字符任一次
.* 匹配任意长度的任意字符(注意贪婪模式,比如 grep “r.*t” /etc/passwd )
x\{m,n\} 指定前面的字符至少出现m次,至多出现N次。
x\{m,\} 指定前面的字符至少出现m次
x\{0,n\} 指定前面的字符至多出现N次
x\{m\} 精确匹配m次
? 匹配其前面的字符0或1次
三.锚定符
1.^ 锚定行首 grep "^r..t" /etc/passwd
2.$ 锚定行尾 grep "h$" /etc/passwd
3.^$ 锚定空白行 grep "^$" /etc/passwd
4.\< (\b) 锚定词首 grep "\<r..t" /etc/passwd
5.\> (\b) 锚定词首 grep "r..t\>" /etc/passwd
示例(容易混淆):
至少包含一个空白字符 grep "[[:space:]]\{1,\}" /etc/passwd
至少包含一个非空白字符 grep "[^[:space:]]\{1,\}" /etc/passwd
没有一个空白字符 grep -v "[^[:space:]]\{1,\}" /etc/passwd
6.\(\)对字符分组 grep "\(l..e\).*\1r"
示例:
grep --color "l\([13]\):\1:.*:\1" /etc/inittab
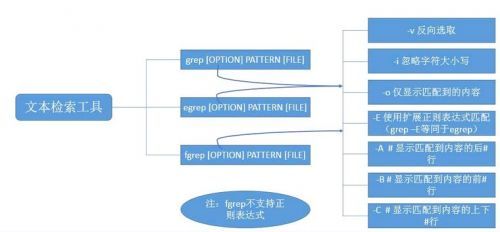
四.选项
-v 对结果取反
-i 忽略字母大小写
-o 仅显示匹配到的字符串(行的其他内容不显示)
-E 支持扩展的正则表达式
-A n 显示匹配到的行下面n行
-B n 显示匹配到的行上面n行
-C n 显示匹配到的行上下面各显示n行




